自己数据集训练的yolo,在电脑端测试精度有90+,但是在板子上基本识别不出来,识别出来了也是错误的结果,然后跟手册不一样的地方在于,我的数据集hand_gesture_dataset只有10个类,然后在这里我没有修改names里的内容,想的是只用到前10个标签名字,是不是这里有问题?
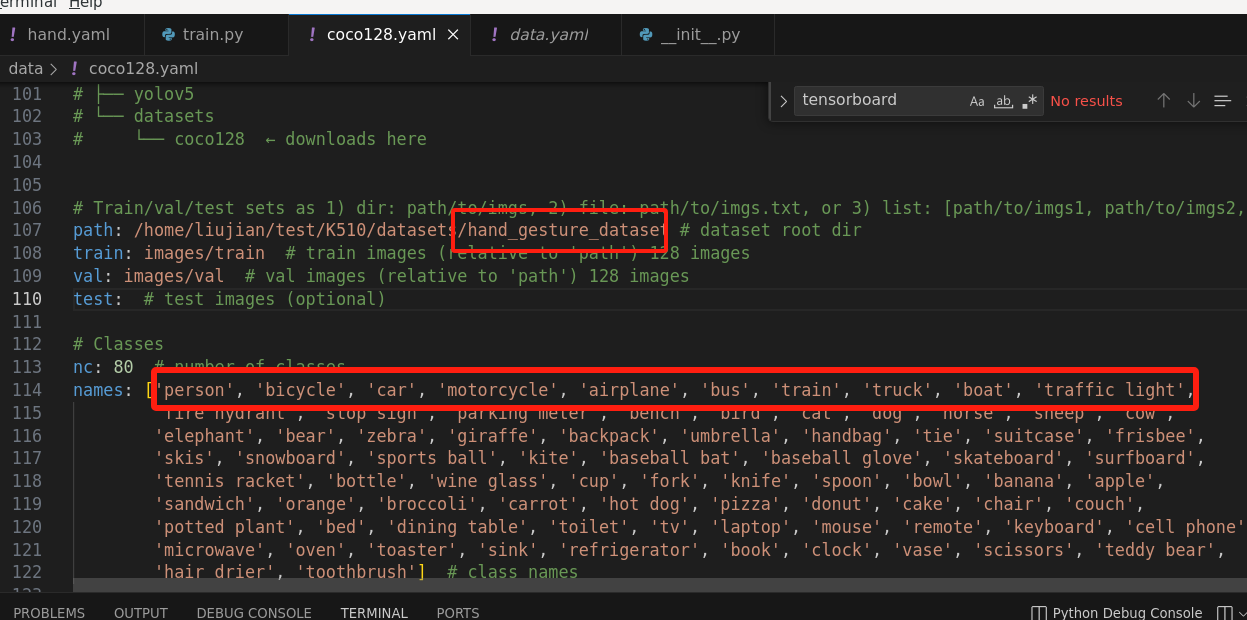
您自己都怀疑这里有问题了,那就修改这部分。如果您不熟悉深度学习,可以使用我们提供模型训练平台
文档教程:
视频教程:
额这部分已经修改了,全程都是按照你们网站的步骤来的
现在得到的结果还是一样怎么办?
你现在的意思是说要用 AI Matrix重新训练?
如果您不熟悉深度学习,可以使用我们提供模型训练平台
不是 我就用的你们给的yolo 换了个数据集而已 该改的都改了 哪里有问题你就说哪里的问题
1.数据集
2.标签
3.输入尺寸
我这边无法预知您的问题在哪里?所以十分抱歉,我确实无法判断问题在哪里。
数据集是没问题的,标签的话打标签的操作那里肯定没问题,后面有别的地方会出问题吗?输入尺寸的话除了640就是320吧?有支持别的参数吗
我们有提供示例工程5_DongshanPI-Vision_嵌入式AI应用开发资料
或者可以查看客服给您发的资料,里面有配套的视频教程
有个奇怪的现象,在进行目标检测的时候,只在屏幕的一侧边缘才会被检测到,而且检测画的框像是因为屏幕不够大,没有把整个目标框起来,这是为什么呢
抱歉,没看懂您在说什么。请您重新组织语言提问,并提供更多信息
就是检测的时候,物体并不是在任何地方都会被检测到,只有当物体在摄像头视线的某一区域才会被检测到,我这里的问题就是只在边缘区域才会被检测到,而且一般检测到后会将目标物体周围画框,从屏幕里可以观察,正常下框线应该包裹住整个物体,但是在这里只会框住部分,给人一种框线的坐标在屏幕外的感觉
我这边只能给您建议是:
1.可能是数据集的问题
2.可以获取输出的坐标定位问题
有没有可能是代码的问题?因为在软件训练过程中在pc一直有用测试集检验,都是正确的,准确度也很高,每次都是上板就出问题
您好,代码是芯片原厂提供的。如果您怀疑代码问题,可自行前往官方途径下载源码: kendryte/k510_buildroot: Kendryte K510 SDK (github.com)
训练的图片一定要是k510自己拍出来的吗?或者对于用来训练的图片尺寸格式有什么要求吗?
如果是设备拍出来的可能会更好,训练尺寸没有要求
有让它连续拍照并存下来的例程吗
你直接使用opencv操作吧,板子默认支持了opencv