DongshanPI-AICT开发板部署YOLOV5自训练模型
0.前言
本章讲述如何训练自定义数据集生成模型,部署到DongshanPI-AICT开发板上。这里假设您已经搭建好YOLOV5-V6.0的环境,搭建环境参考:YOLOV5-V6.0环境搭建。
下面操作仅演示如何去训练自定义模型、导出模型、转换模型、模型部署。注意:训练模型对于电脑需要有一定的要求,如果电脑性能较弱可能会导致训练效果较差,从而导致模型精度较低。
参考链接:Train YOLOv5 on Custom Data | Ultralytics Docs
测试体验镜像:v853_linux_100ask_uart0.img(yolov5-100ask <模型文件> <测试图像>)
模型文件:network_binary.nb
yolov5-100ask应用包:yolov5-100ask.tar.gz
1.下载数据标注工具
数据标注工具:Releases · HumanSignal/labelImg · GitHub
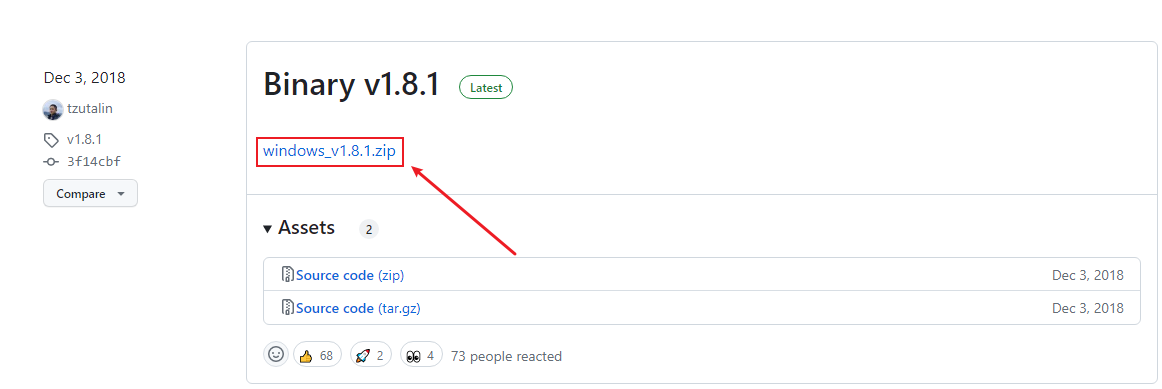
点击上述红框下载,下载完成后解压压缩包,双击打开labelImg.exe文件。

打开后等待运行,运行完成后会进入如下标注工作界面。

关于LabelImg更多的使用方法,请访问:https://github.com/heartexlabs/labelImg
由于LabelImg会预先提供一些类供您使用,需要手动删除这些类,使得您可以标注自己的数据集。步骤如下所示:
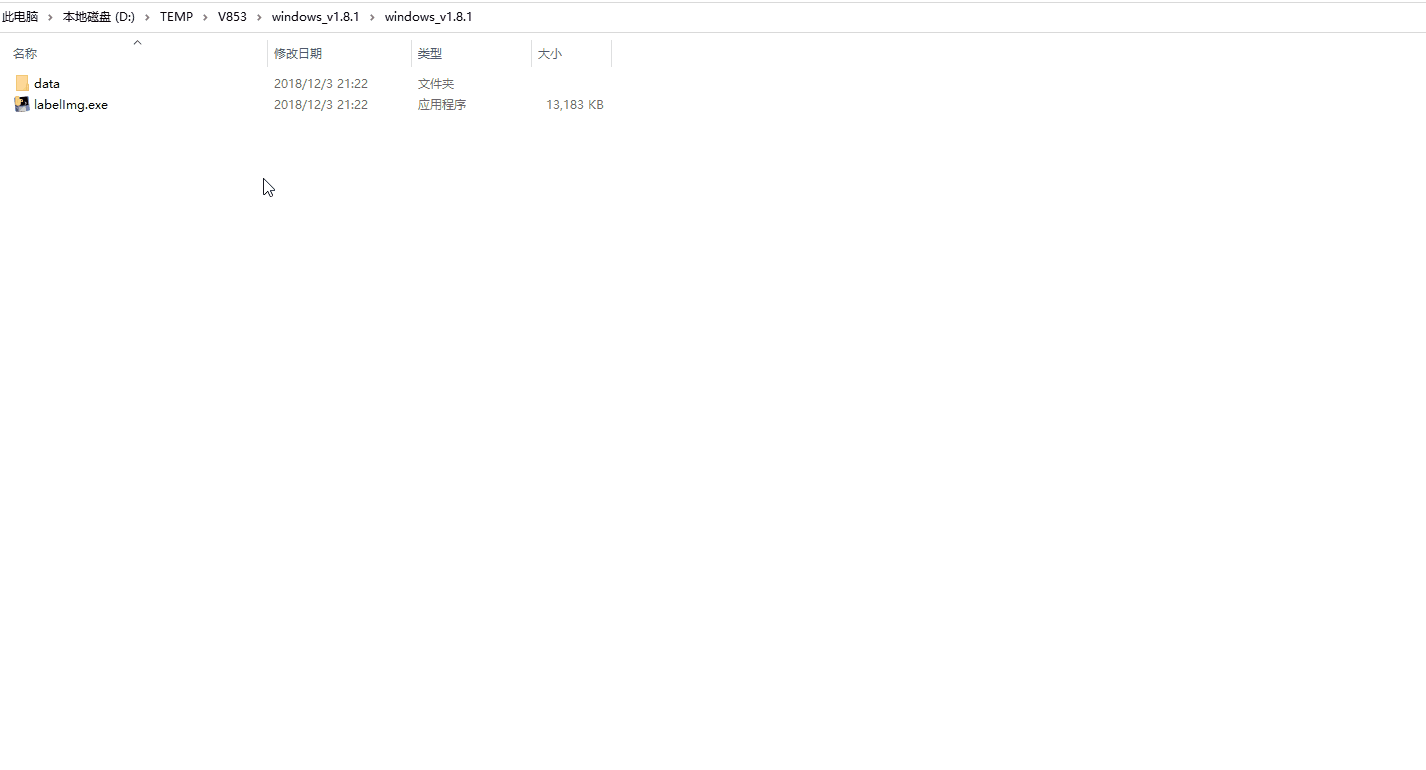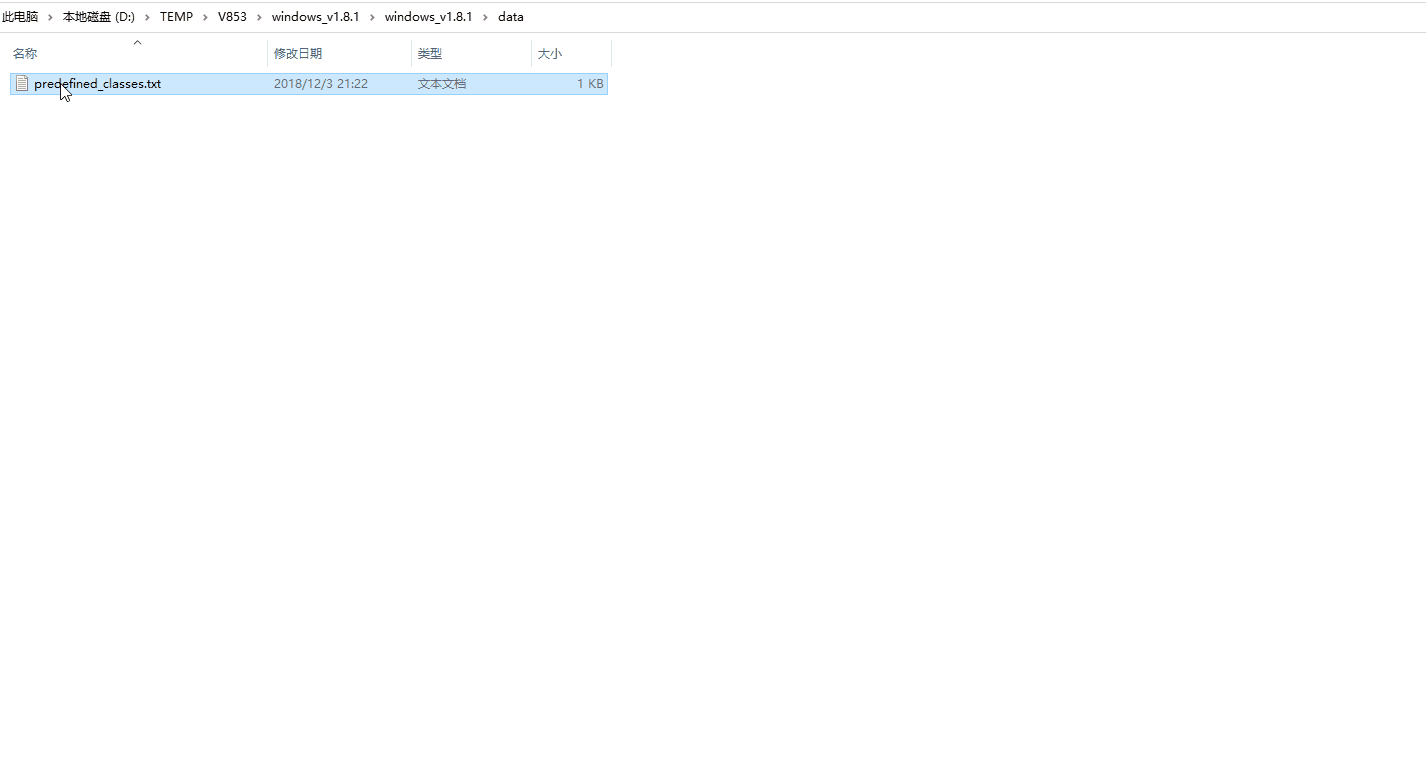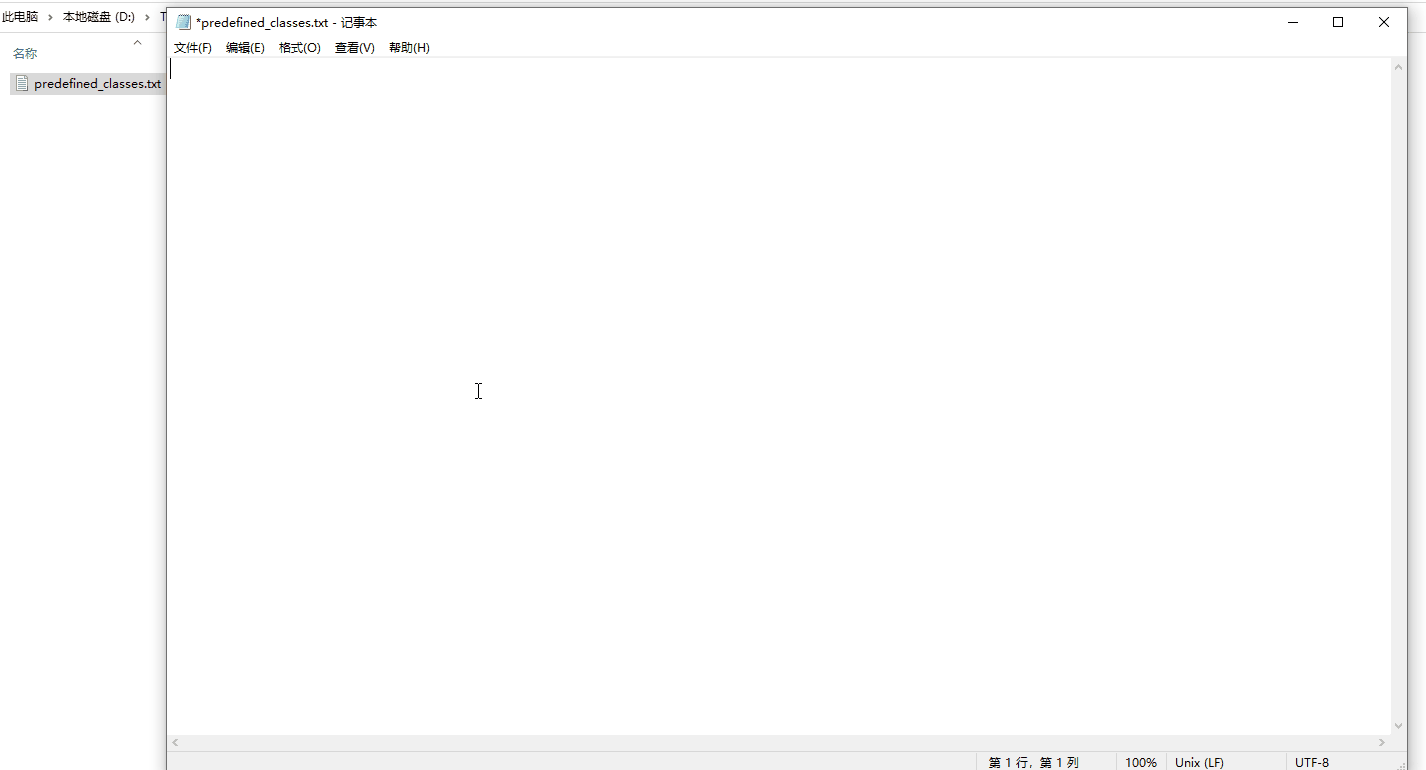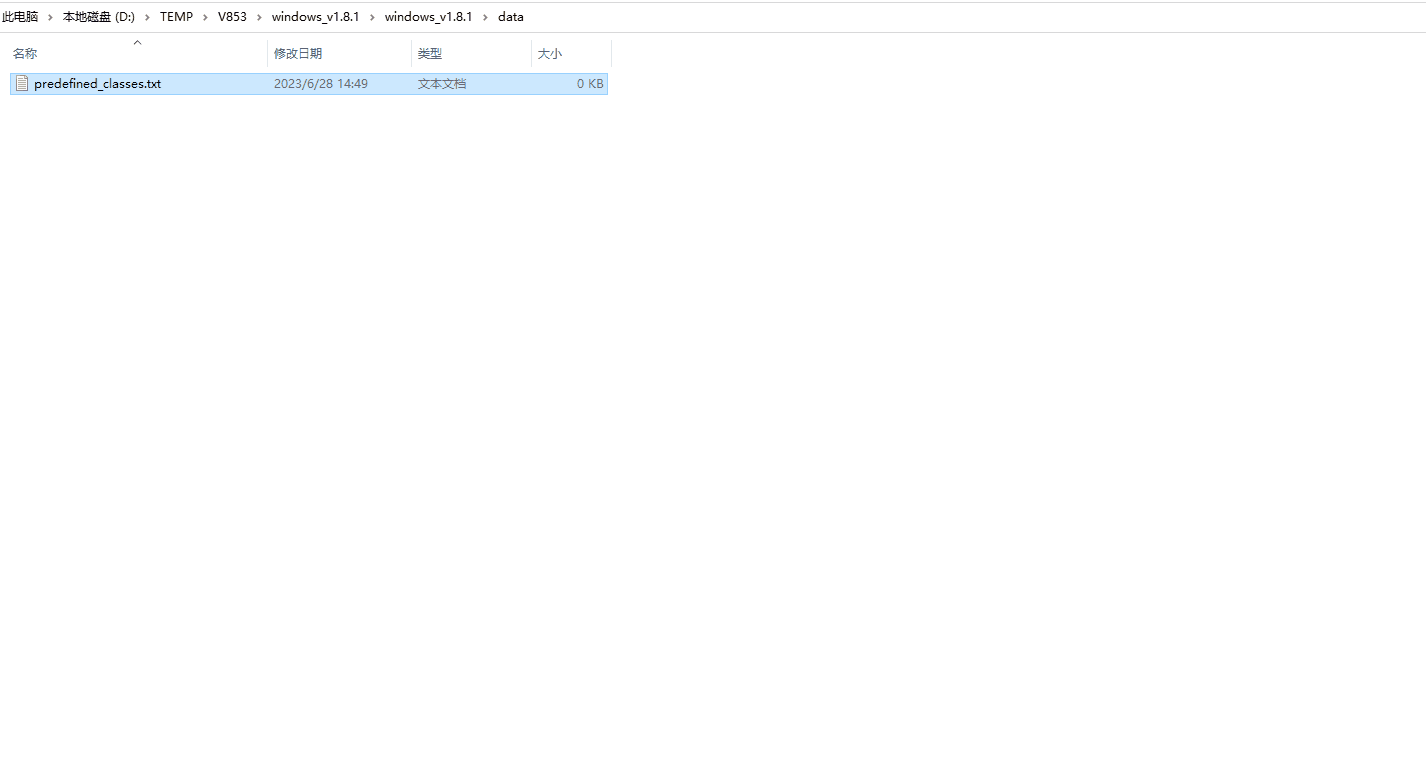
进入LabelImg程序目录中的data目录中,打开predefined_classes.txt文件,删除文件中所有预定义的类后保存并退出即可。
2.创建数据集目录
在任意工作目录中创建images文件夹和labels文件夹分别存放图像数据集和标注信息。这里我演示仅使用少量图像样本进行标注,在实际项目中需要采集足够的图像进行标注才拿满足模型的准确率和精度。
例如我在100ask-yolov5-image目录中创建有images文件夹和labels文件夹,如下所示,创建images文件,存放图像数据集,创建labels文件夹,该文件夹用于后续存放标注数据。
3.标注图像
打开LabelImg软件后,使用软件打开数据集图像文件夹,如下所示:

打开后,修改输出label的文件夹为我们创建的数据集目录下的labels文件夹
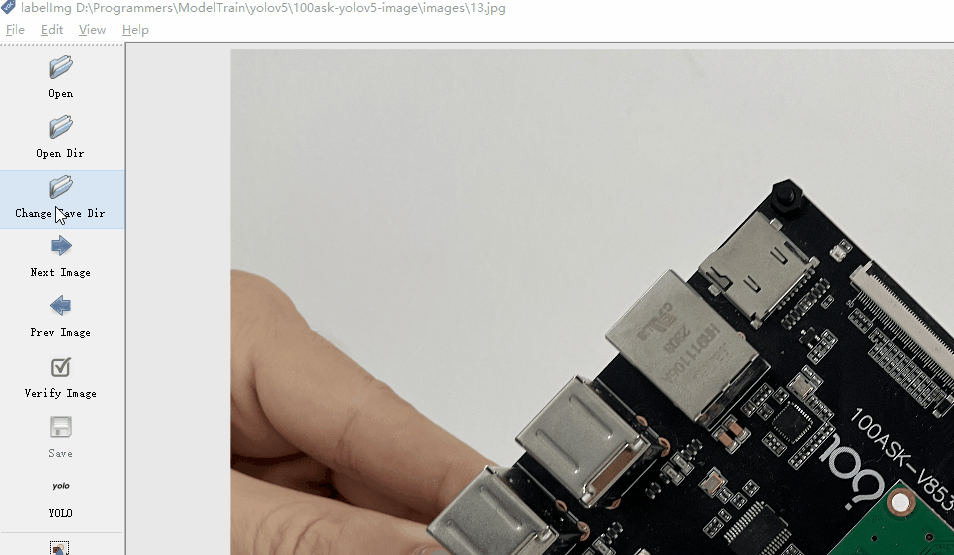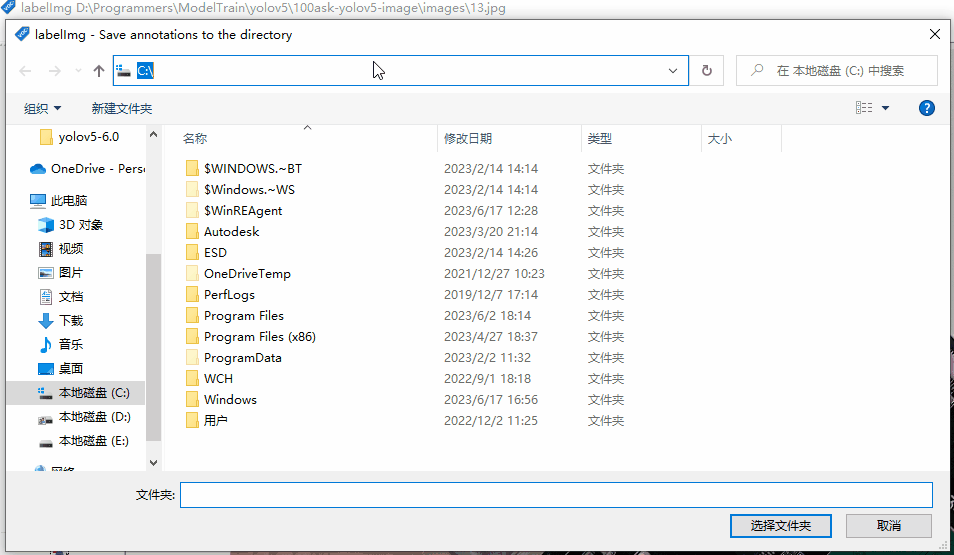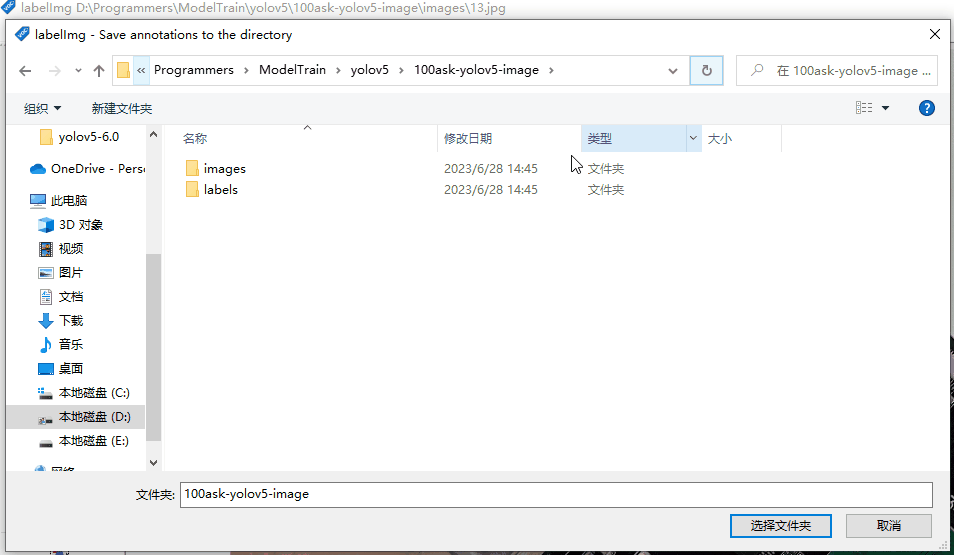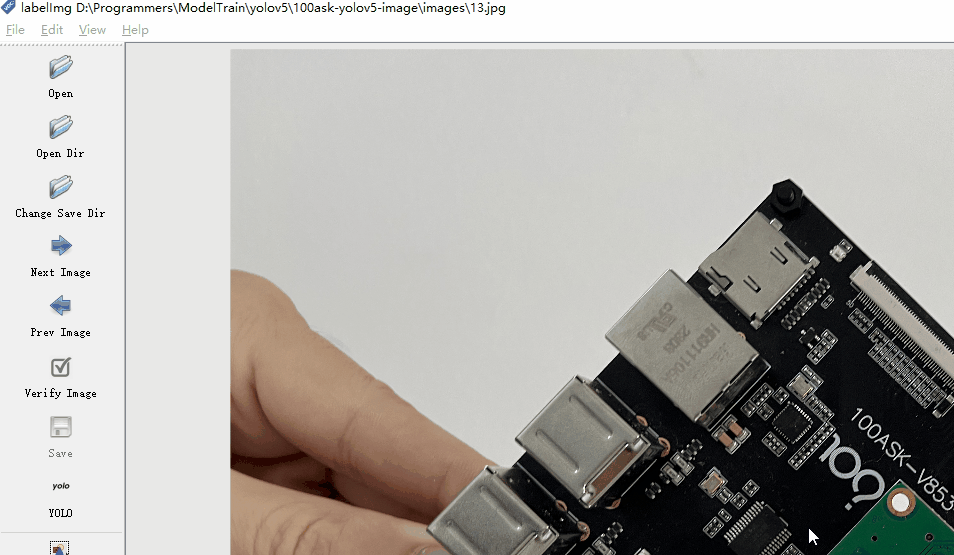
下面我演示标注过程,以百问网的开发板为例,标注三块开发板
当你点击Save后即表示标注完成,标注完成后后会在labels目录下生成classes.txt(类别)和图像中标注的类别即位置信息。
下面为LabelImg快捷键目录:
| Ctrl + u | Load all of the images from a directory |
|---|---|
| Ctrl + r | Change the default annotation target dir |
| Ctrl + s | Save |
| Ctrl + d | Copy the current label and rect box |
| Ctrl + Shift + d | Delete the current image |
| Space | Flag the current image as verified |
| w | Create a rect box |
| d | Next image |
| a | Previous image |
| del | Delete the selected rect box |
| Ctrl++ | Zoom in |
经过标注大量的图像后,labels文件夹如下图所示
4.划分训练集和验证集
在模型训练中,需要有训练集和验证集。可以简单理解为网络使用训练集去训练,训练出来的网络使用验证集验证。在总数据集中训练集通常应占80%,验证集应占20%。所以将我们标注的数据集按比例进行分配。
在yolov5-6.0项目目录下创建100ask文件夹(该文件夹名可自定义),在100ask文件夹中创建train文件夹(存放训练集)和创建val文件夹(存放验证集)
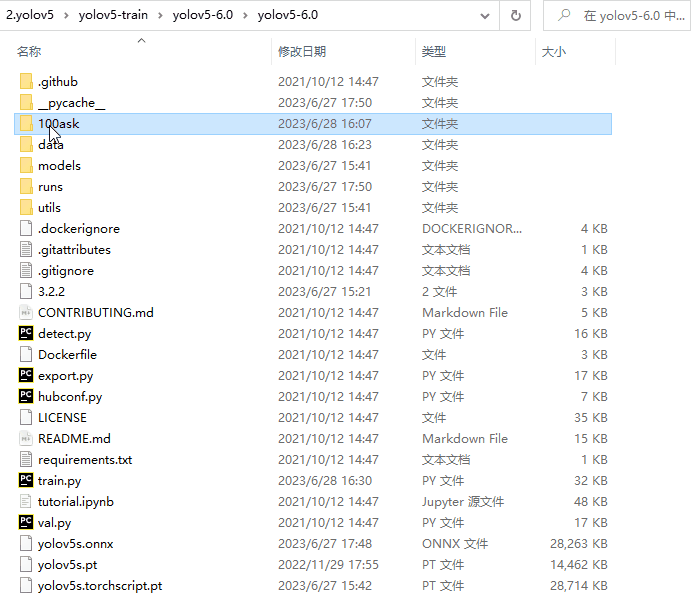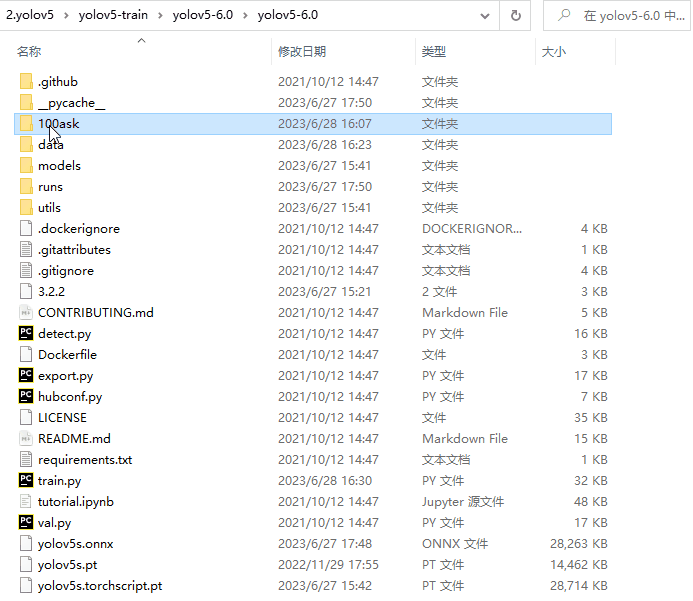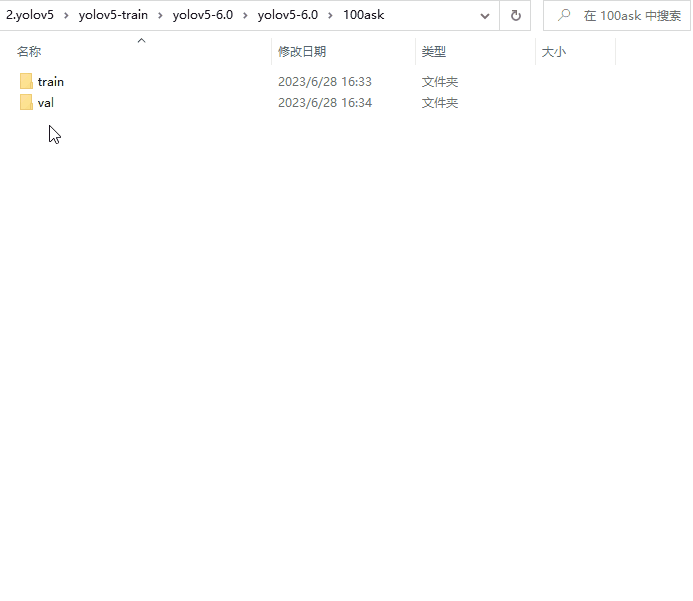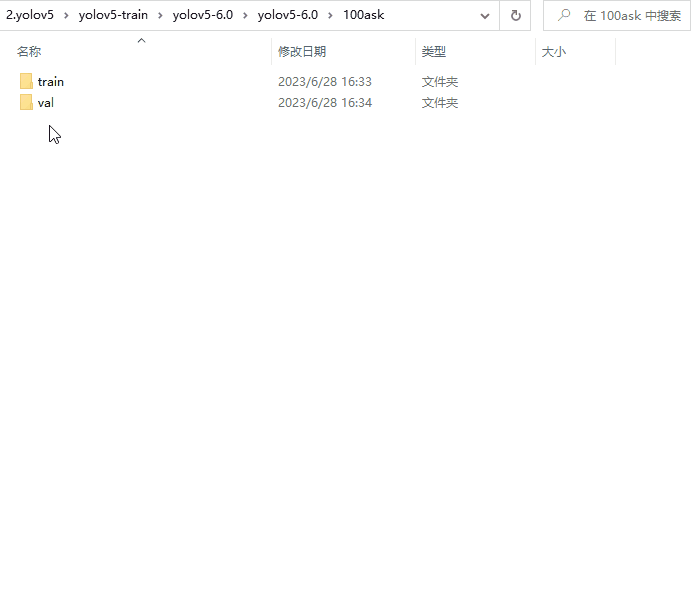
在train文件夹中创建images文件夹和labels文件夹。其中images文件夹存放总数据集的80%的图像文件,labels文件夹存放与images中的文件对应的标注文件。
在val文件夹中创建images文件夹和labels文件夹。其中images文件夹存放总数据集的20%的图像文件,labels文件夹存放与images中的文件对应的标注文件。
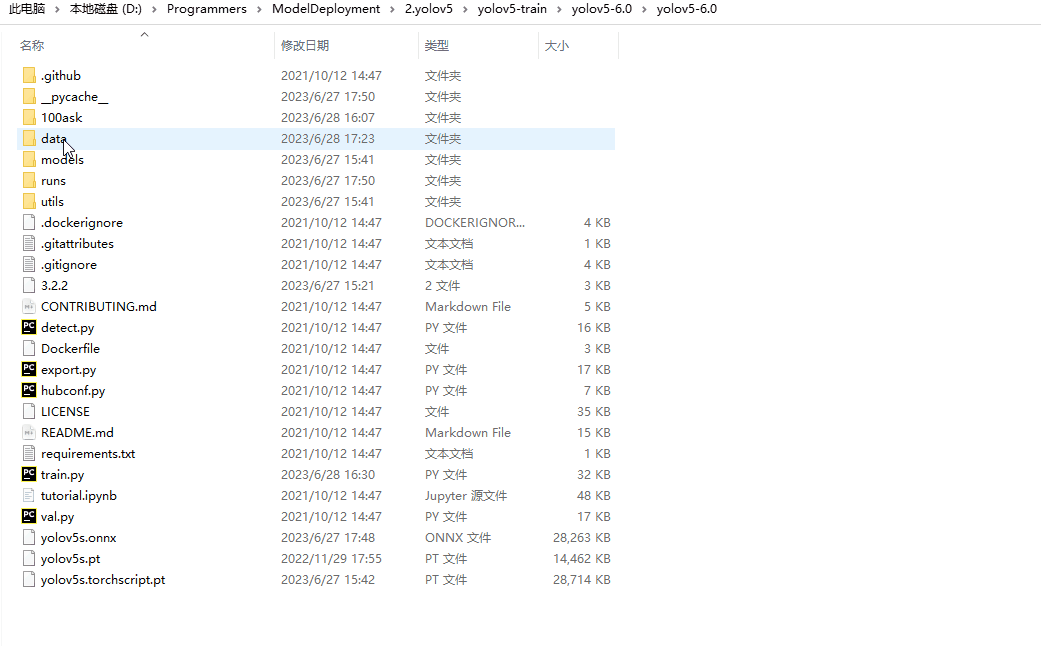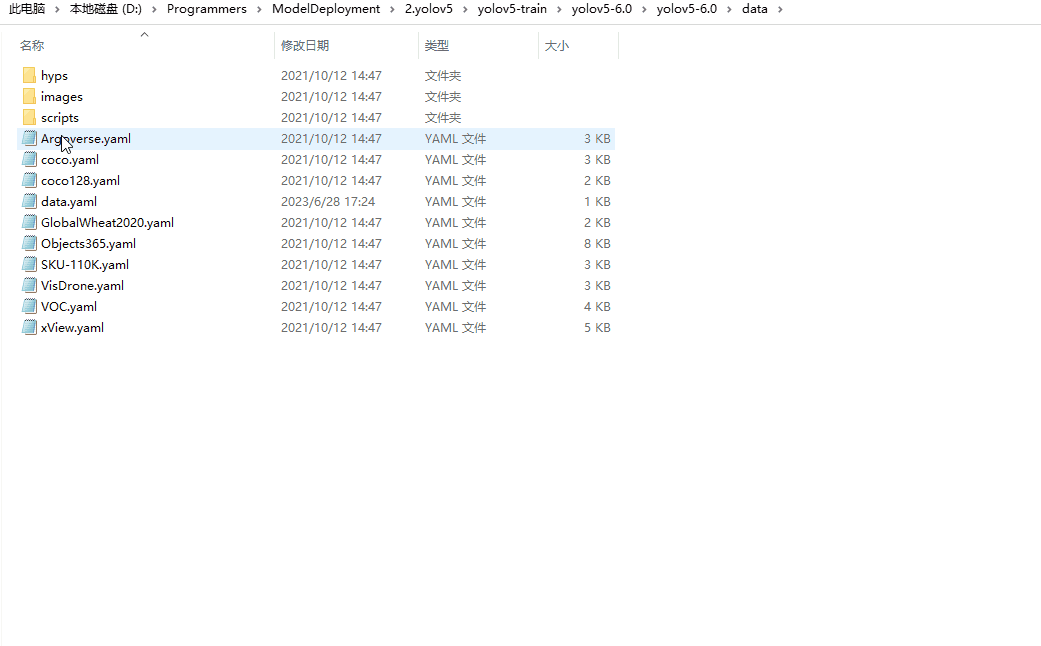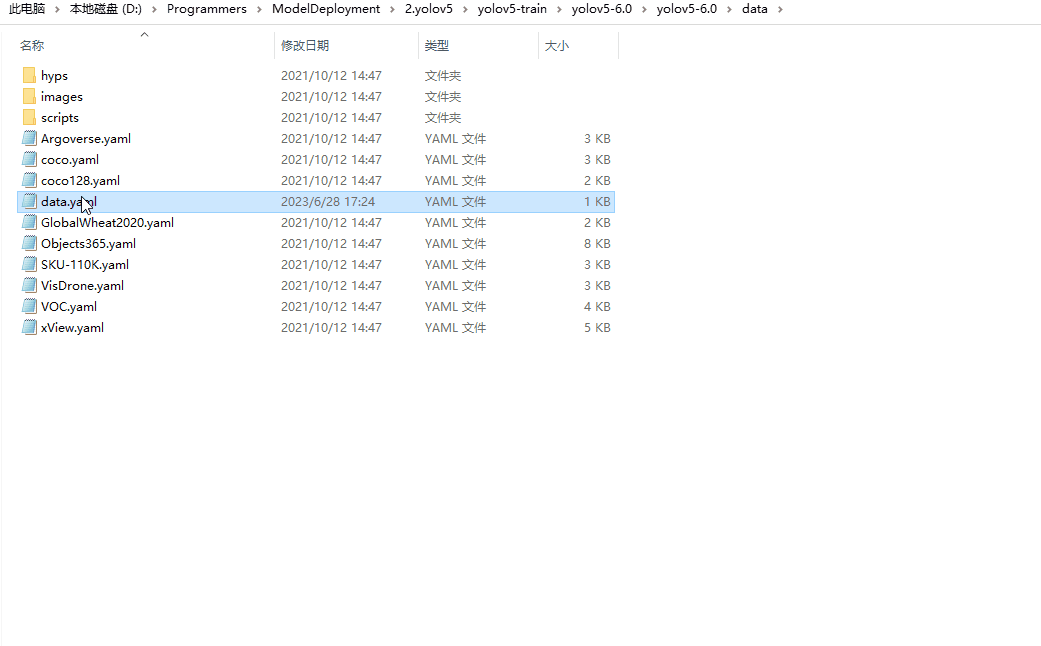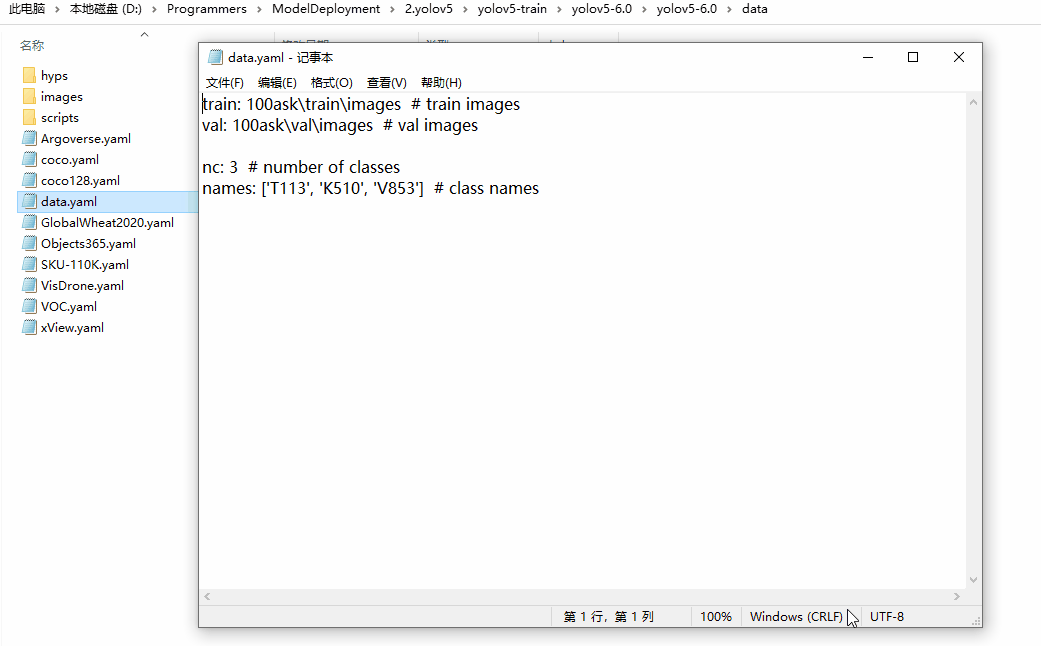
5.创建数据集配置文件
进入yolov5-6.0\data目录下,创建data.yaml,文件内容如下所示:
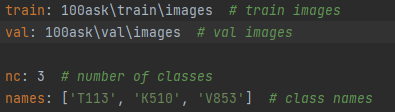
train: 100ask\train\images # train images
val: 100ask\val\images # val images
nc: 3 # number of classes
names: ['T113', 'K510', 'V853'] # class names
6.创建模型配置文件
进入models目录下,拷贝yolov5s.yaml文件,粘贴并models目录下重命名为100ask_my-model.yaml,例如:
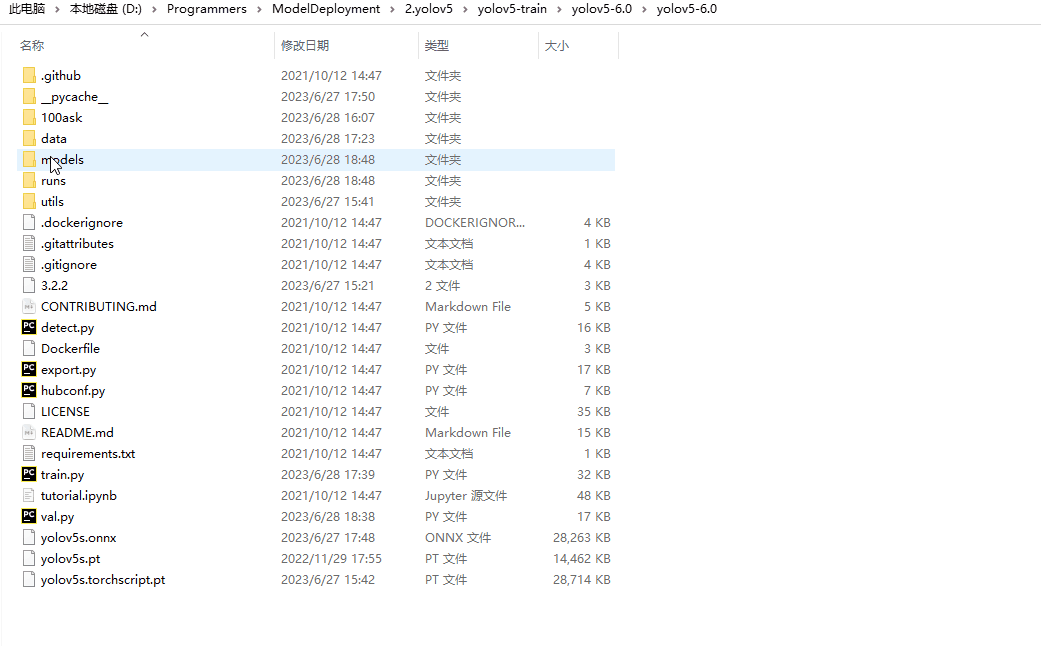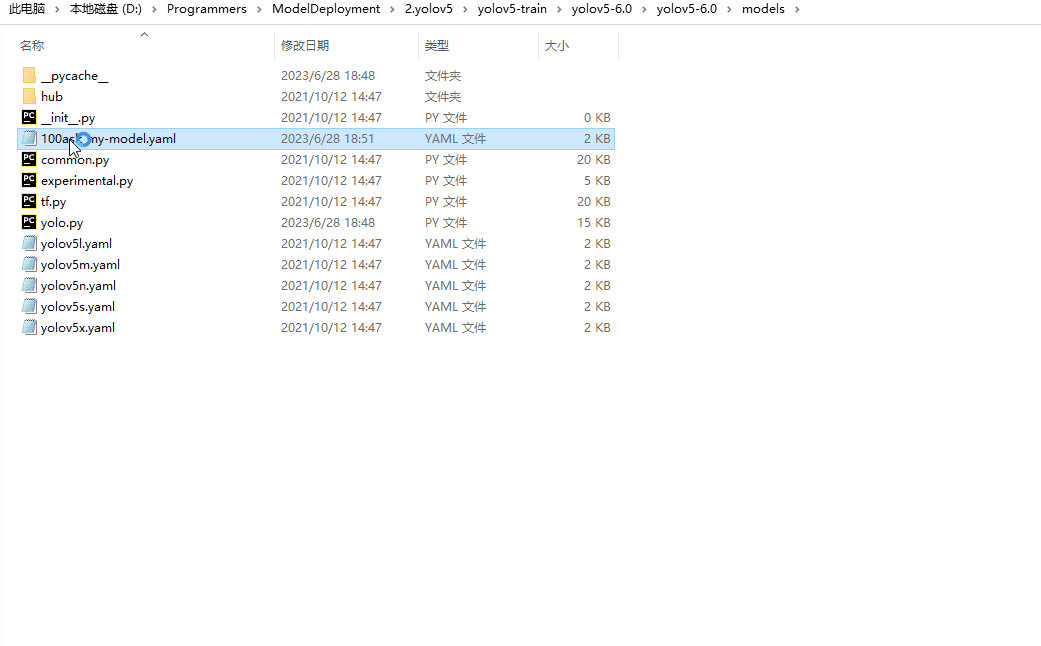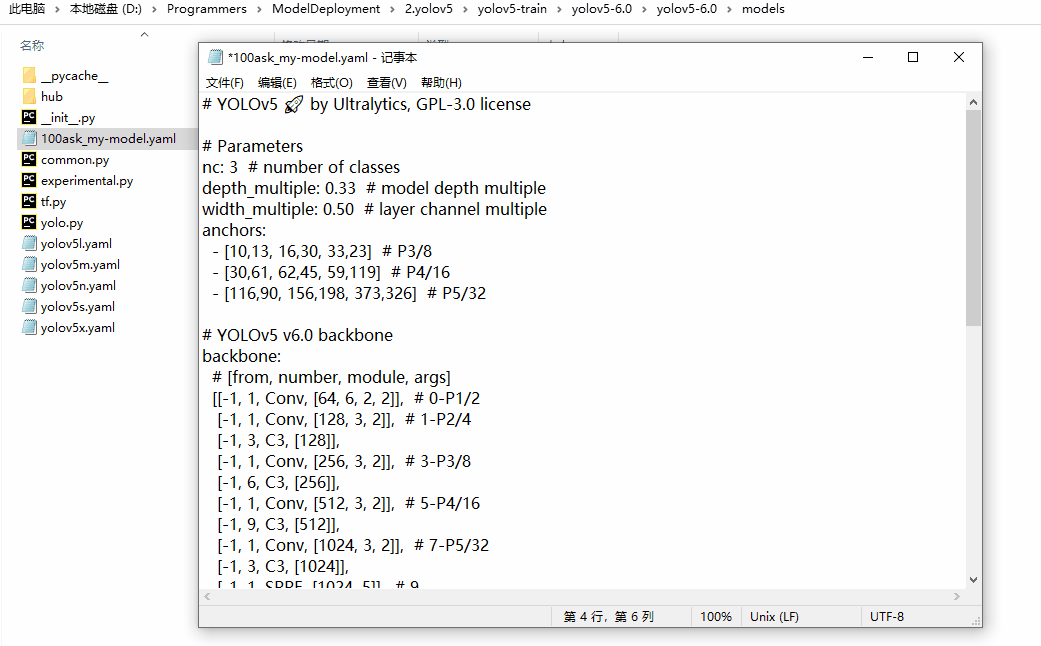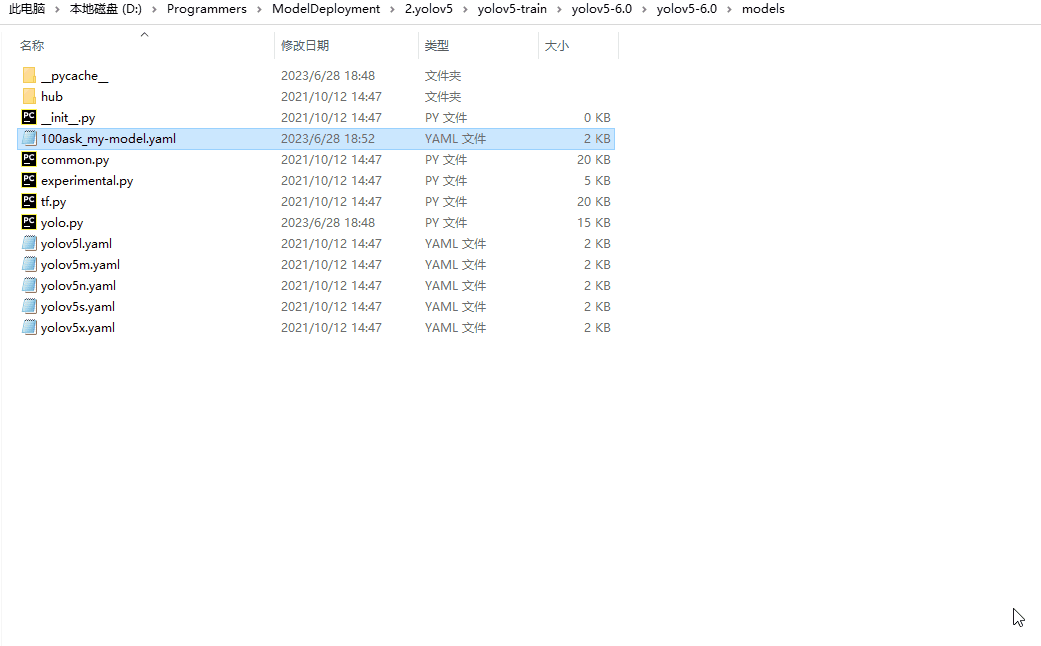
修改100ask_my-model.yaml中类的数目为自己训练模型的类数目。
6.修改训练函数
打开yolov5-6.0项目文件夹中的train.py,修改数据配置文件路径,如下图红框所示:
parser.add_argument('--cfg', type=str, default='models/100ask_my-model.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
7.训练模型
在conda终端的激活yolov5环境,激活后进入yolov5-6.0项目文件夹。执行python train.py,如下图所示:
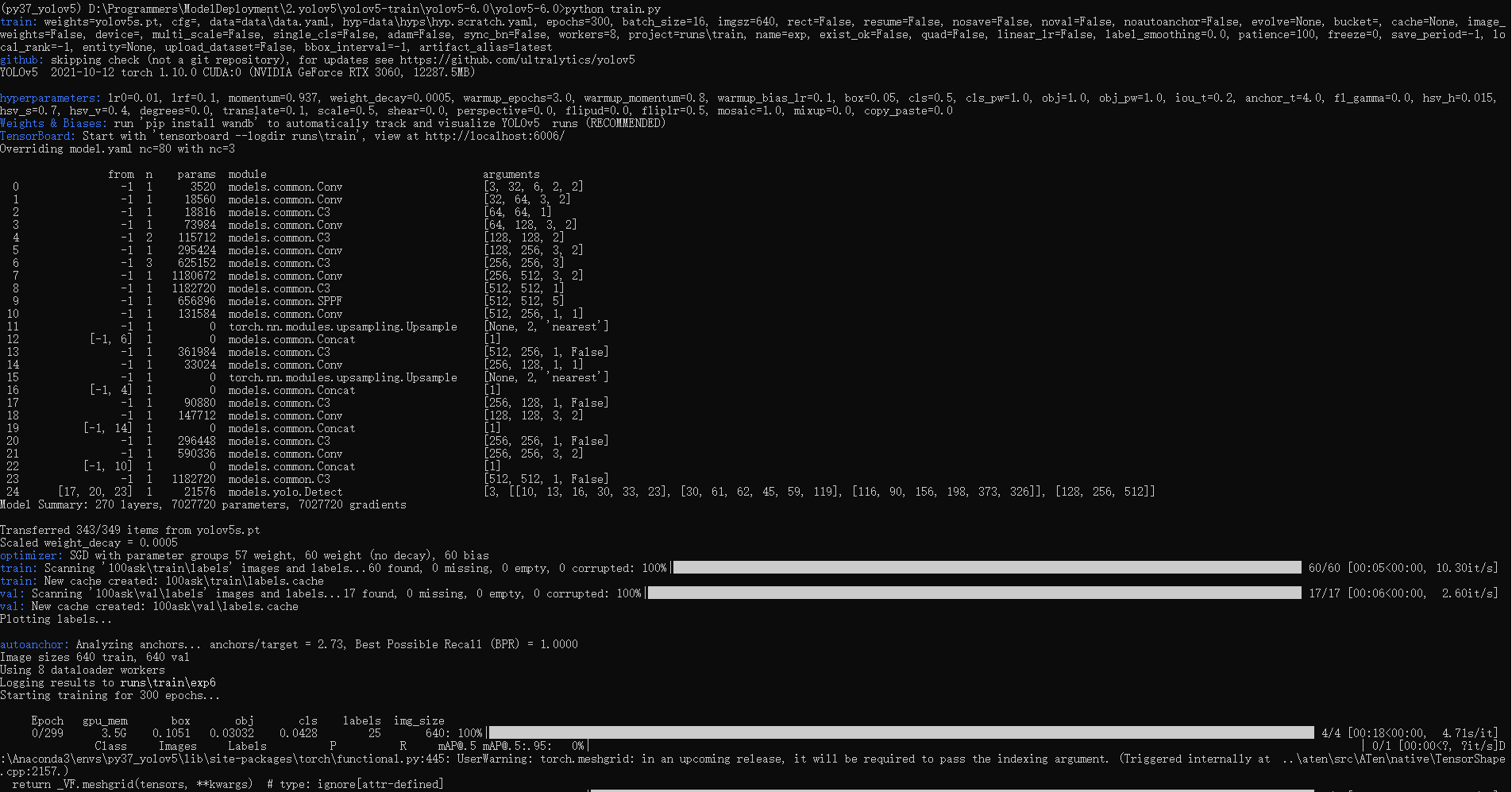
程序默认迭代300次,等待训练完成…

训练完成后结果会保存在runs\train\目录下最新一次的训练结果,如上图所示,此次训练的最好模型和最后训练的模型保存在以下目录中
runs\train\exp7\weights
8.验证模型
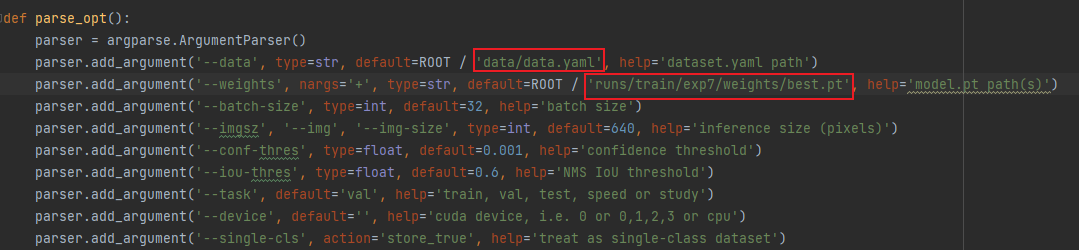
修改val.py函数,修改如下
parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp7/weights/best.pt', help='model.pt path(s)')
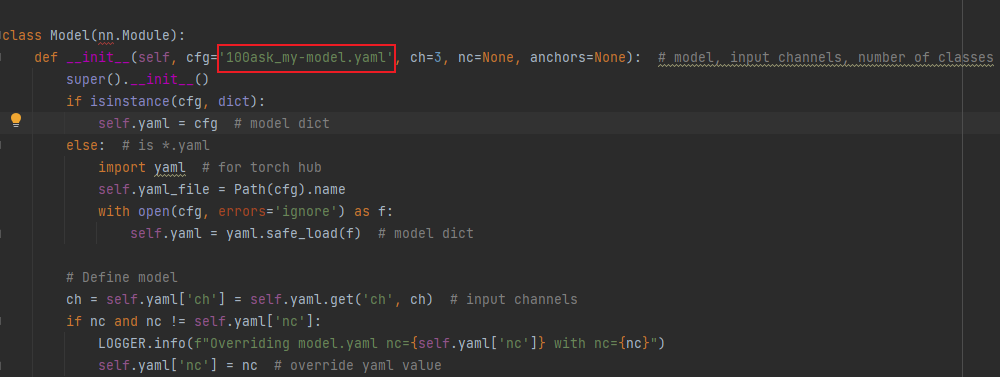
修改models文件夹下的yolo.py
class Model(nn.Module):
def __init__(self, cfg='100ask_my-model.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
打开conda终端输入python val.py

执行完成后的结果保存在runs\val\exp文件下。
9.预测图像
在data目录中新建100ask-images文件夹存放待检测的图像和视频文件。
修改detect.py函数中,模型的路径与检测图像路径。
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp7/weights/best.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/100ask-images', help='file/dir/URL/glob, 0 for webcam')

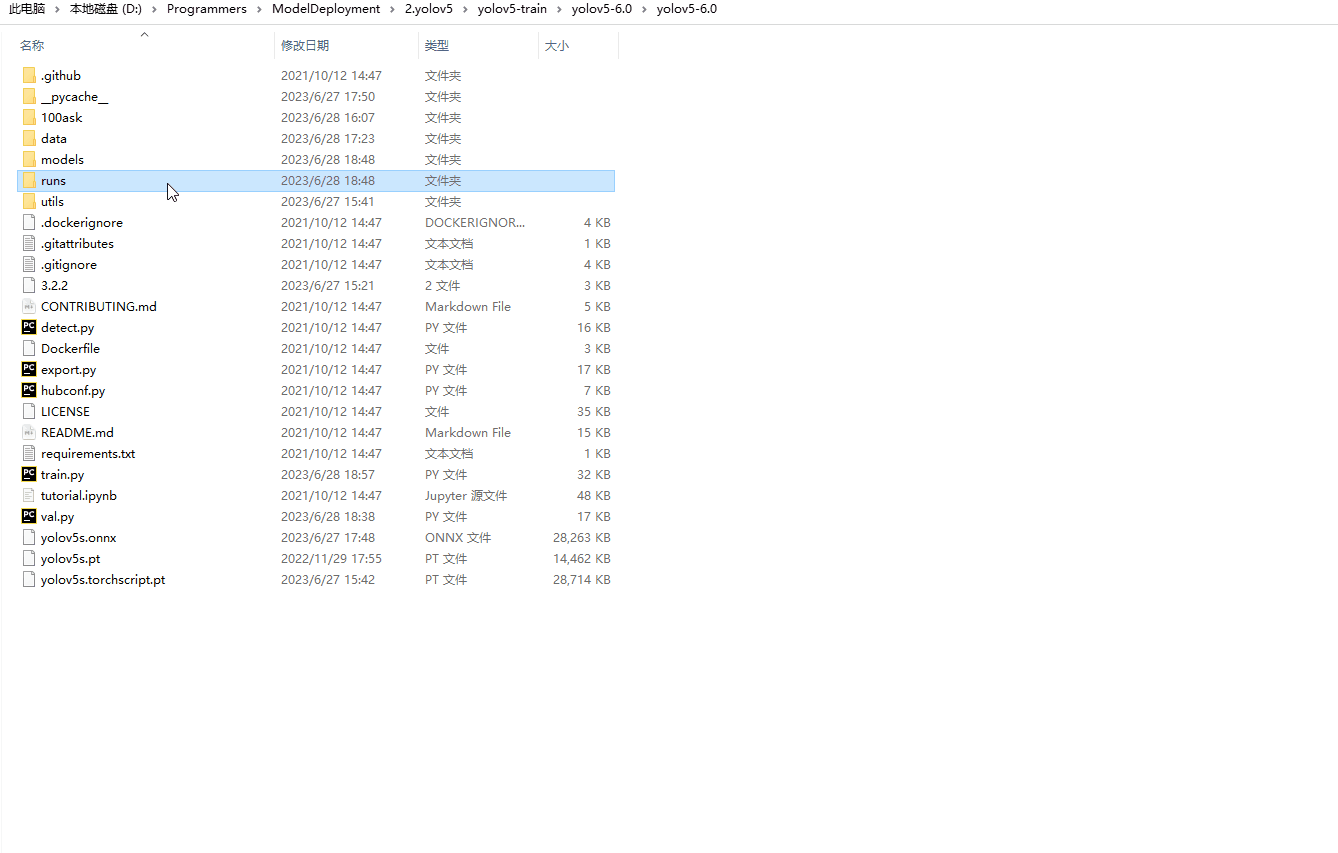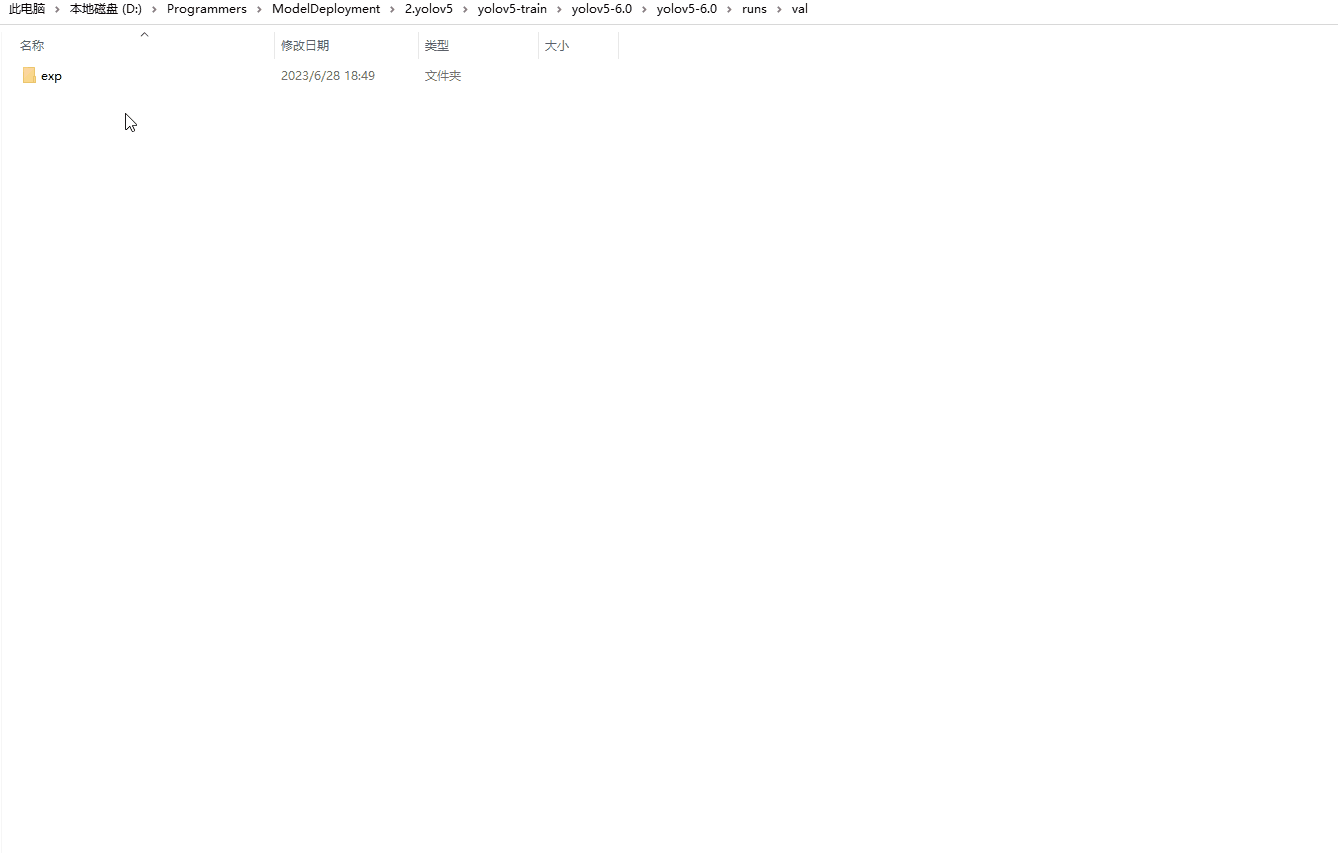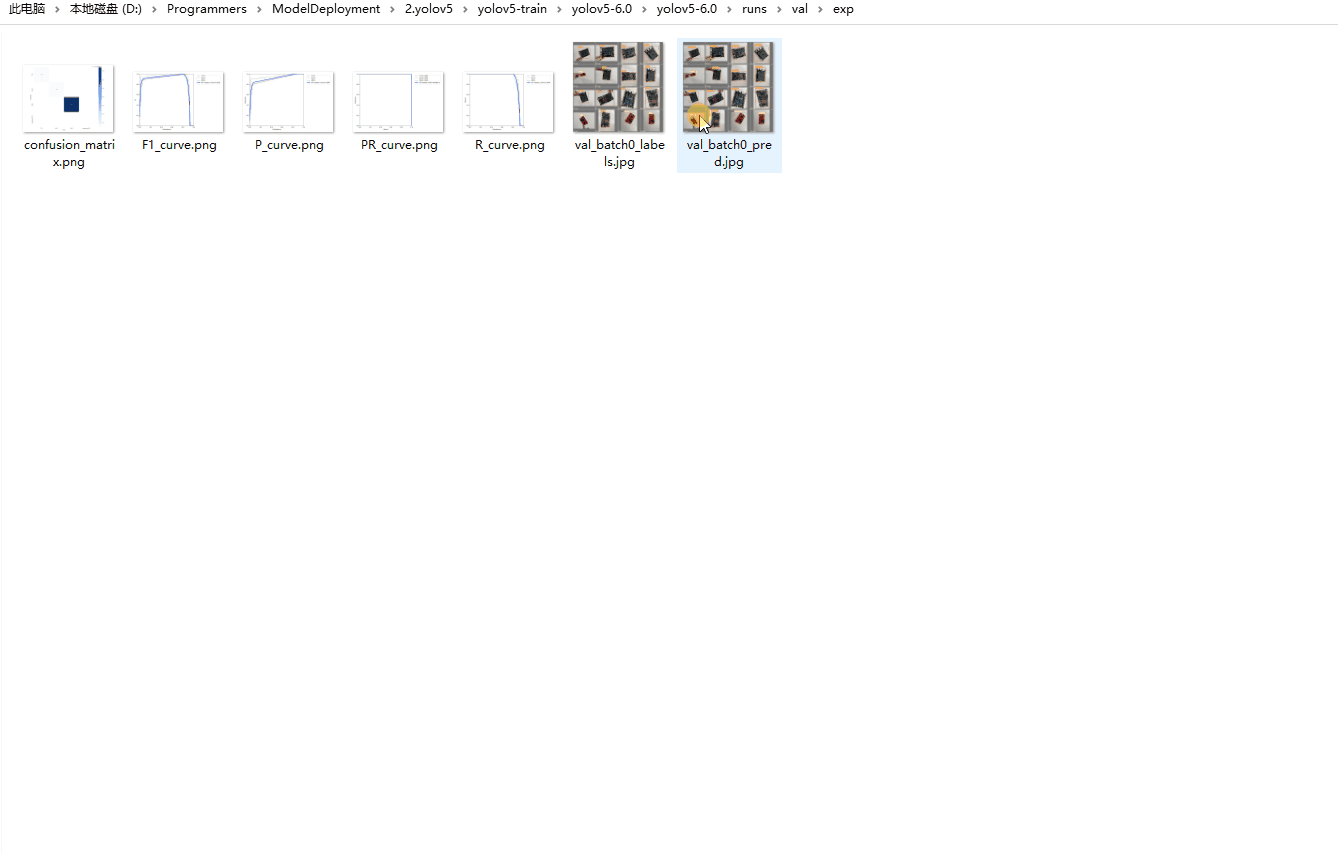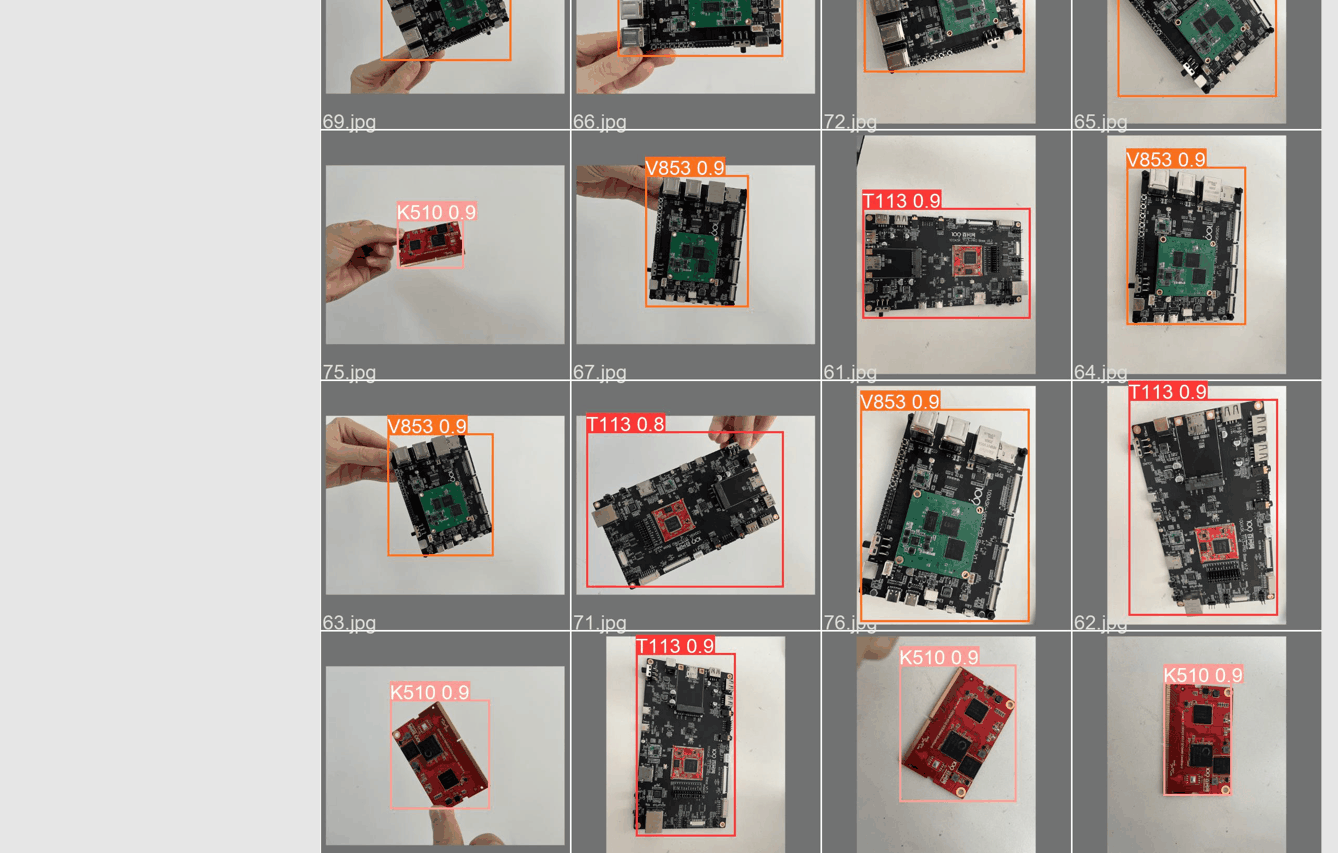
检测效果如下图所示:

10.导出ONNX模型
修改export.py函数
parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
parser.add_argument('--weights', type=str, default=ROOT / 'runs/train/exp7/weights/best.pt', help='weights path')

在conda终端输入:
python export.py --include onnx --dynamic
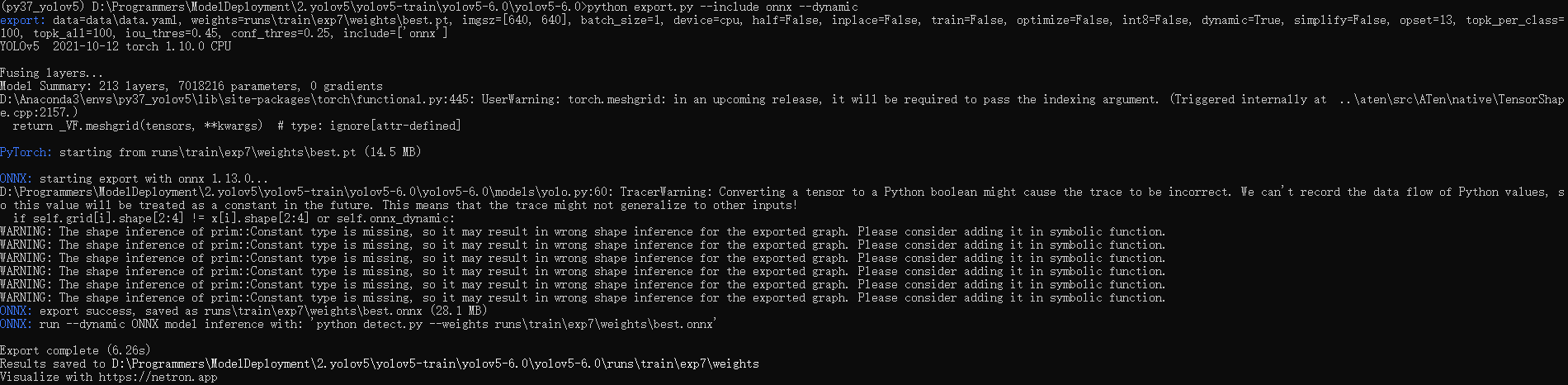
导出的模型会与输入的模型位于同一路径下,假设我输入的模型位于:runs\train\exp7\weights
11.简化模型
简化模型前需要用到onnxruntime依赖包,输入以下命令安装:
pip install onnxruntime==1.13.1 -i https://pypi.doubanio.com/simple/
简化命令如下:
python -m onnxsim <输入模型> <输出模型> --input-shape <输入图像尺寸>
例如:
输入模型路径为runs/train/exp7/weights/best.onnx,输出模型路径为runs/train/exp7/weights/best-sim.onnx
输入图像尺寸固定为640x640。
python -m onnxsim runs/train/exp7/weights/best.onnx runs/train/exp7/weights/best-sim.onnx --input-shape 1,3,640,640
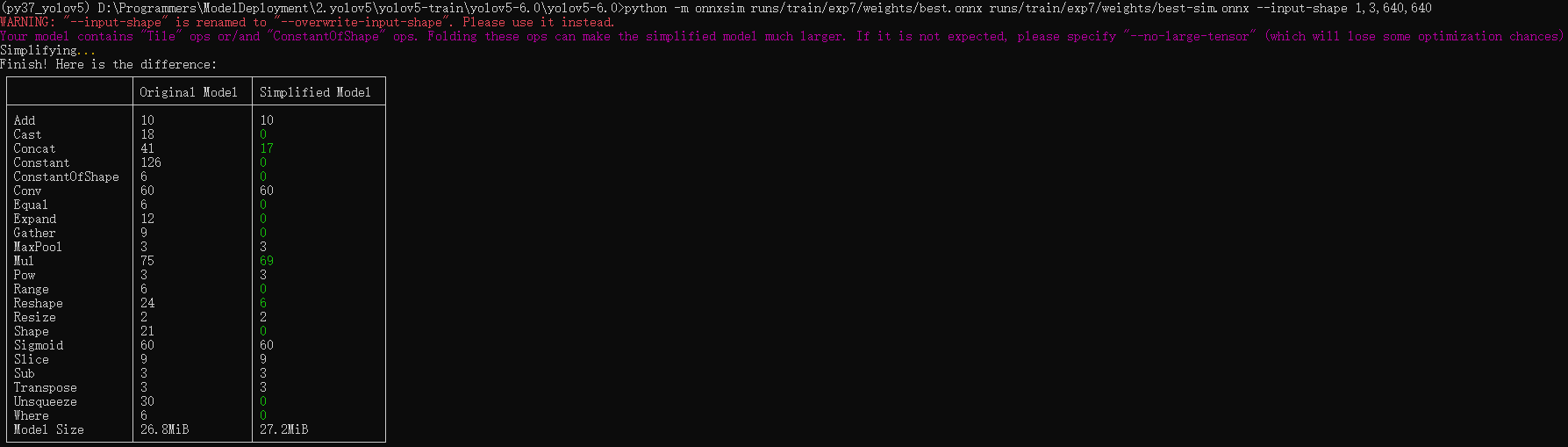
13.查看模型
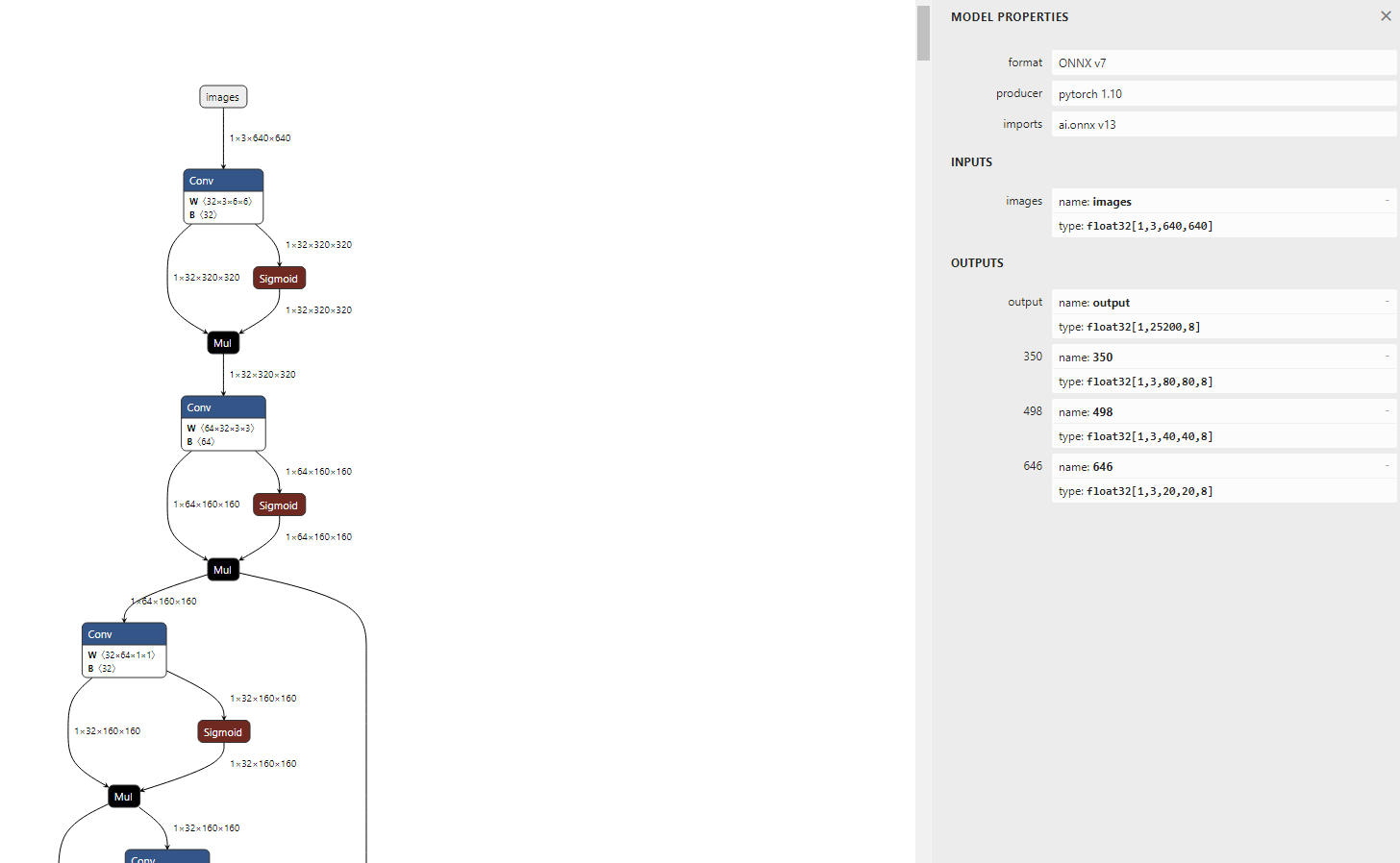
可以看到输入已经固定为640x640,可看到模型有 4 个输出节点,其中 ouput 节点为后处理解析后的节点;在实际测试的过程中,发现 NPU 量化操作后对后处理的运算非常不友好,输出数据偏差较大,所以我们可以将后处理部分放在 CPU 运行;因此在导入模型时保留 350,498, 646 三个后处理解析前的输出节点即可。
14.验证模型
模型需要修改为简化后的模型路径。
新建文件夹存放固定的输入图像尺寸。假设上述中我设置输入图像尺寸为640x640,那么此时我在data目录下新建100ask-images-640文件夹存放640x640的图像作为待测数据。
修改detect.py函数
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp7/weights/best-sim.onnx', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/100ask-images-640', help='file/dir/URL/glob, 0 for webcam')

在conda终端输入:
python detect.py

通过输出信息可知:检测结果存储在runs\detect\exp6
检测结果如下:

15.转换模型
15.1 创建工作目录
将简化后的best-sim.onnx模型传入配置到NPU模型转换工具的虚拟机中,创建模型工具目录,包含模型文件,量化文件夹data(存放量化图片),dataset.txt文件(存放量化图片的路径)。
buntu@ubuntu2004:~/100ask-yolov5-test$ tree
.
├── best-sim.onnx
├── data
│ └── test01.jpg
└── dataset.txt
1 directory, 5 files
工作目录如下所示:
15.2 导入模型
导入模型前需要知道我们要保留的输出节点,由之前查看到我们输出的三个后处理节点为:350,498,646 。
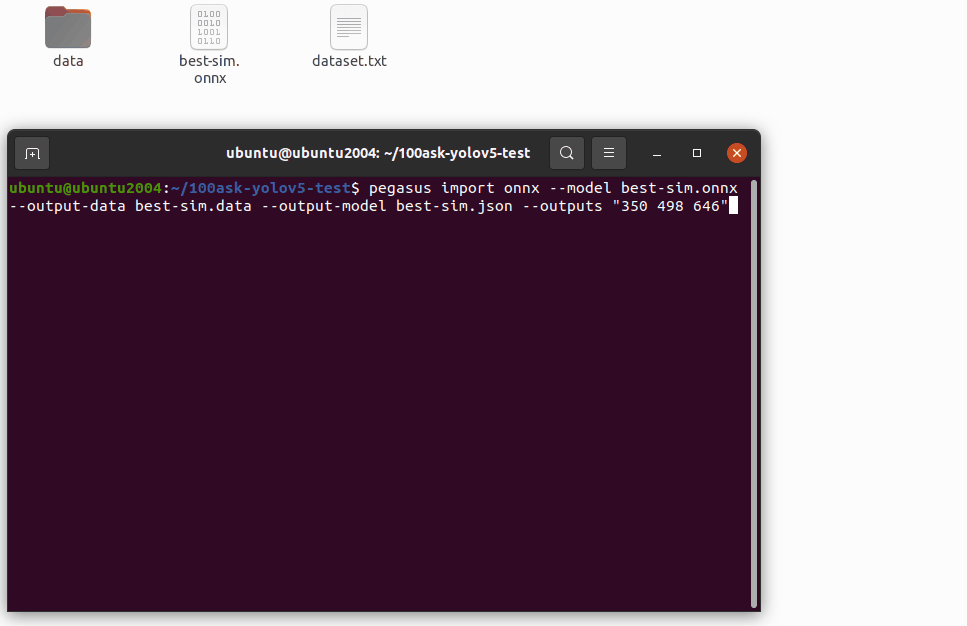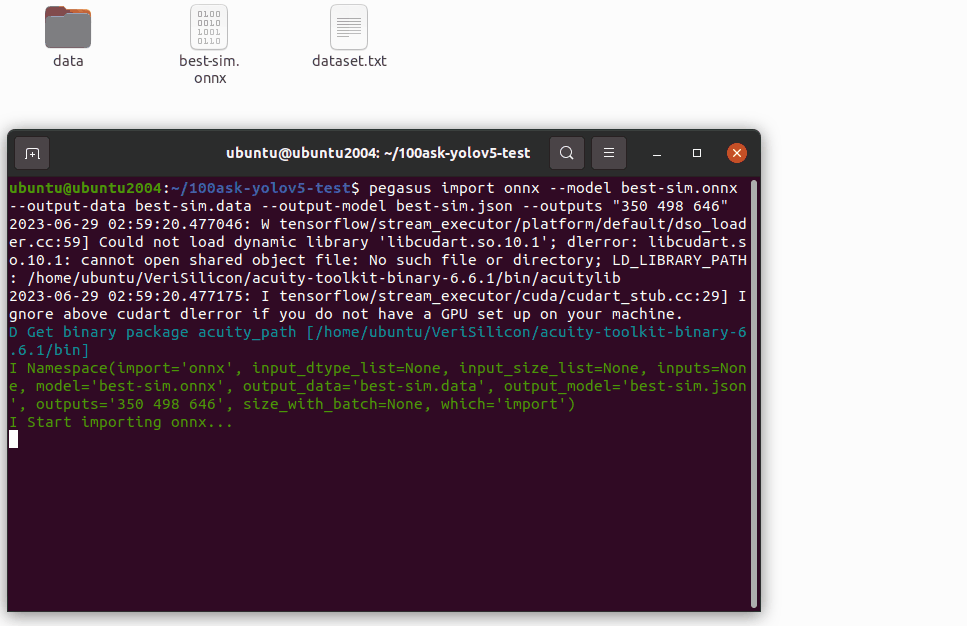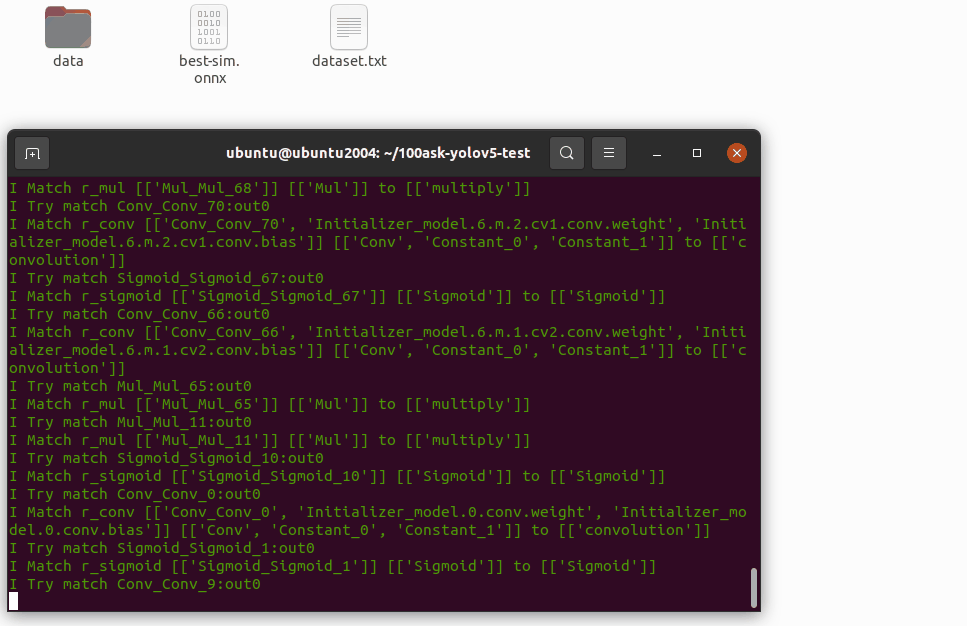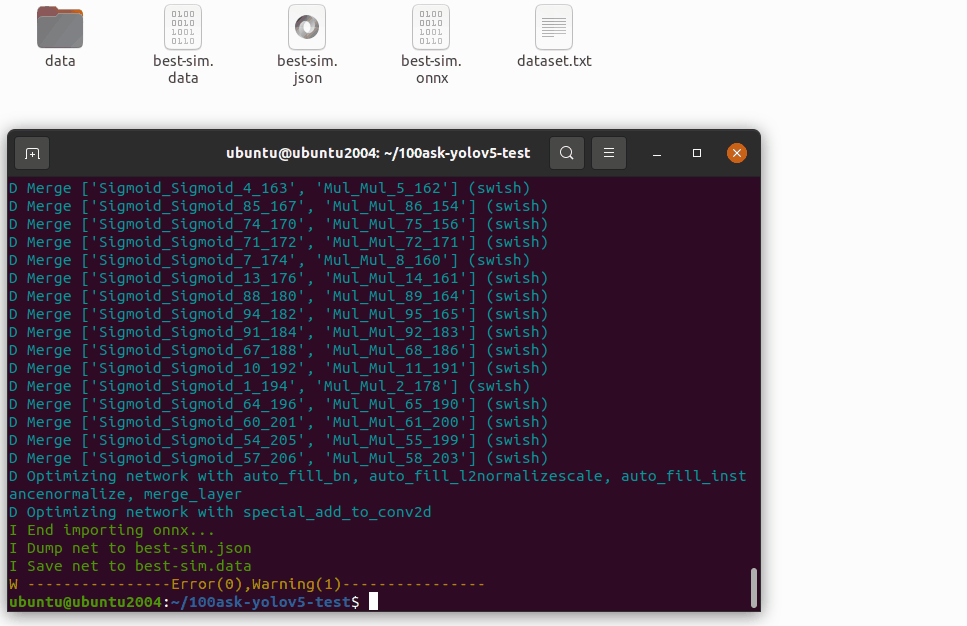
pegasus import onnx --model best-sim.onnx --output-data best-sim.data --output-model best-sim.json --outputs "350 498 646"
导入生成两个文件,分别是是 yolov5s-sim.data 和 yolov5s-sim.json 文件,两个文件是 YOLO V5 网络对应的芯原内部格式表示文件,data 文件储存权重,cfg 文件储存模型。
15.3 生成 YML 文件
YML 文件对网络的输入和输出的超参数进行描述以及配置,这些参数包括,输入输出 tensor 的形状,归一化系数 (均值,零点),图像格式,tensor 的输出格式,后处理方式等等
pegasus generate inputmeta --model best-sim.json --input-meta-output best-sim_inputmeta.yml
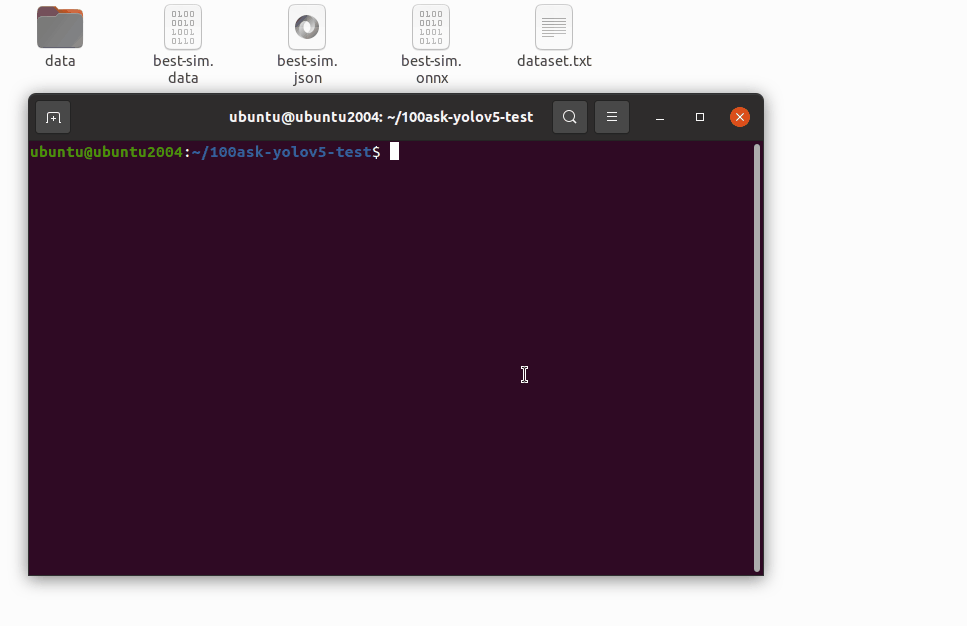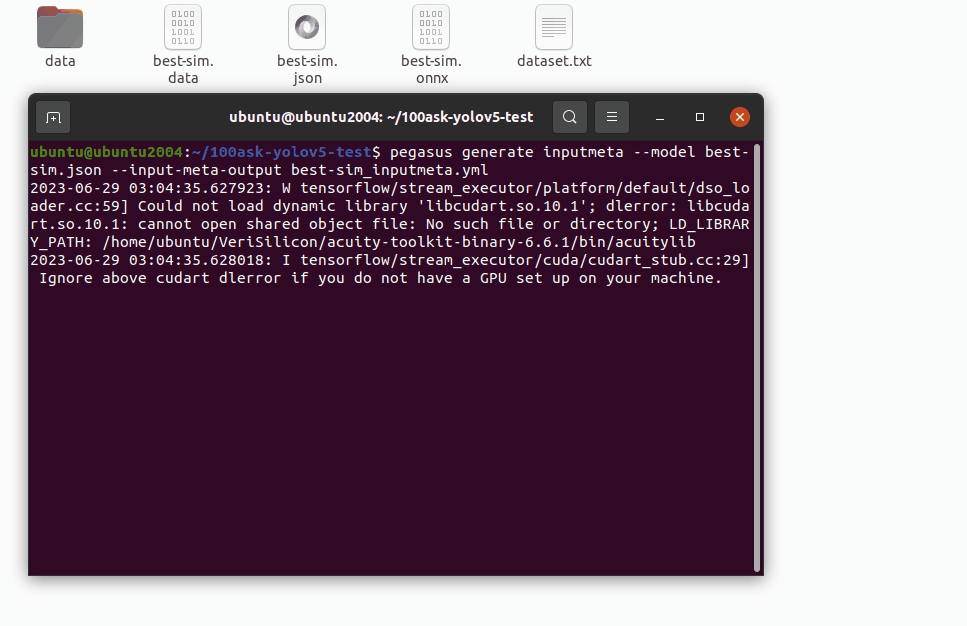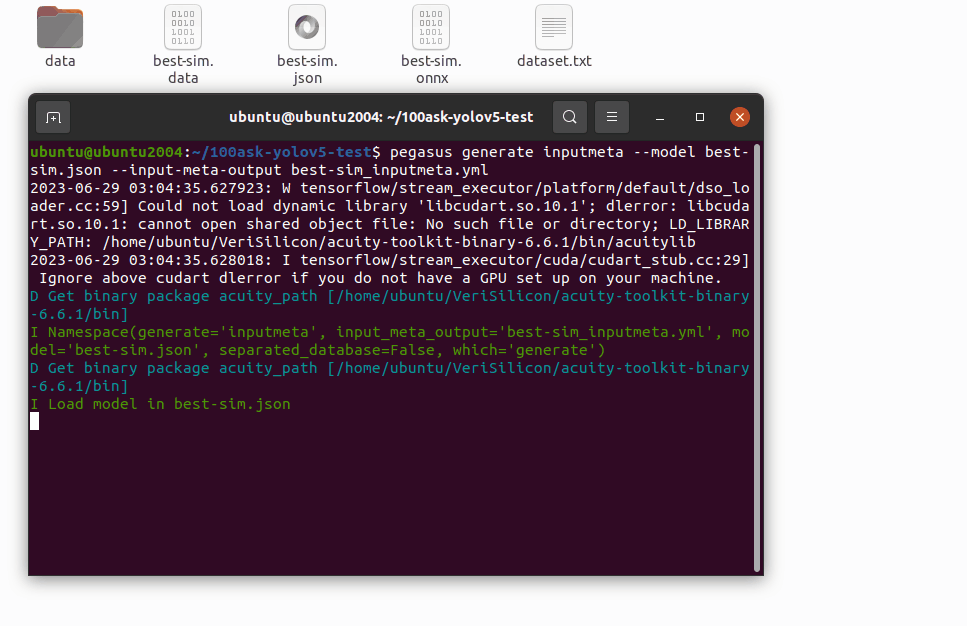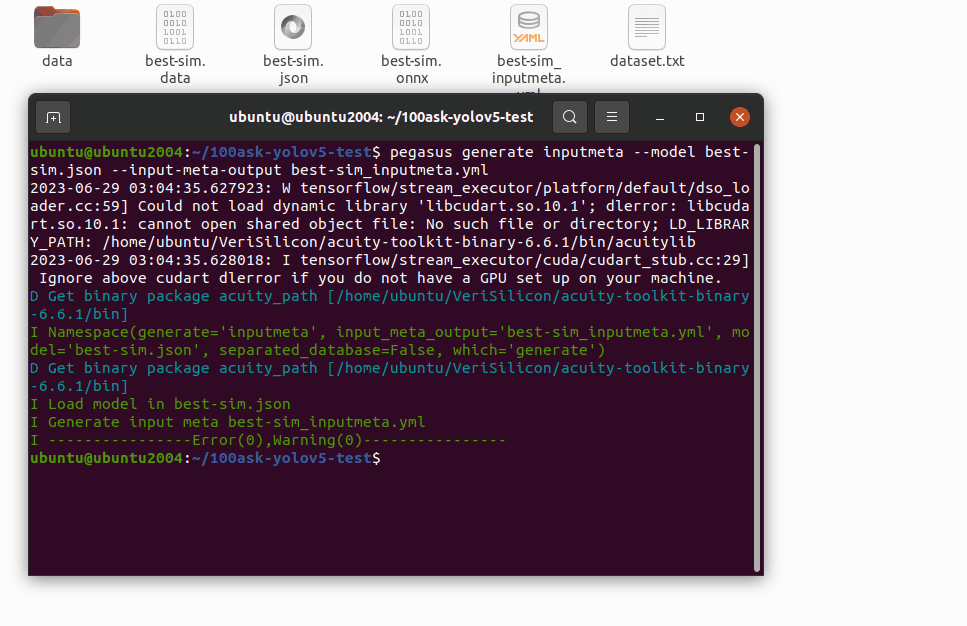
pegasus generate postprocess-file --model best-sim.json --postprocess-file-output best-sim_postprocess_file.yml
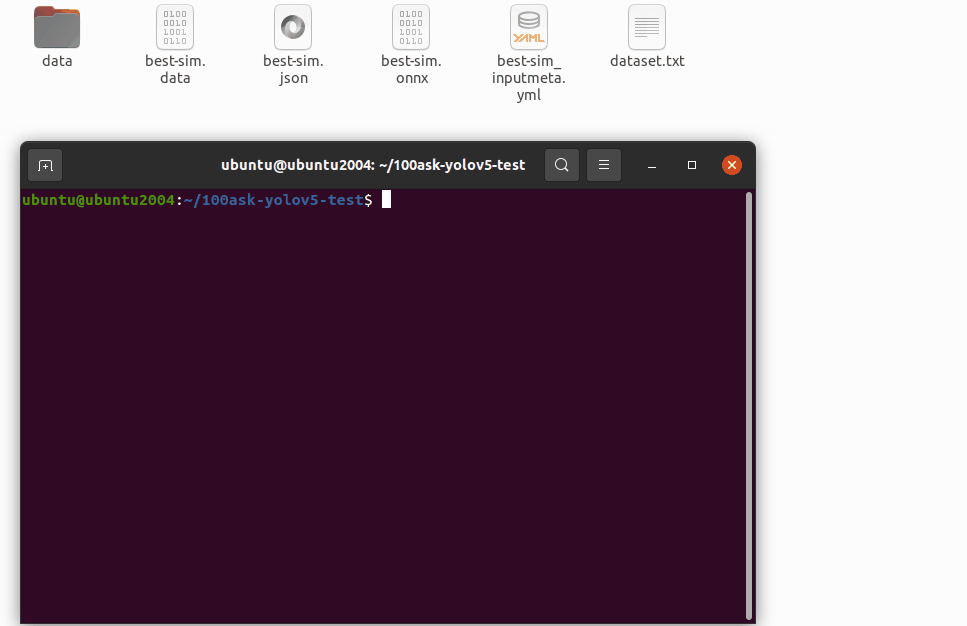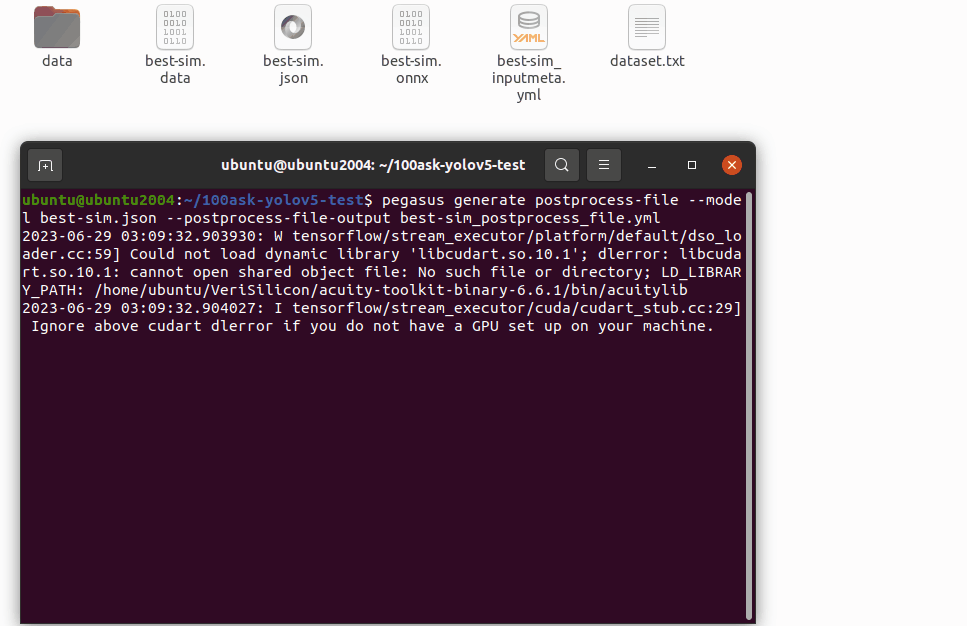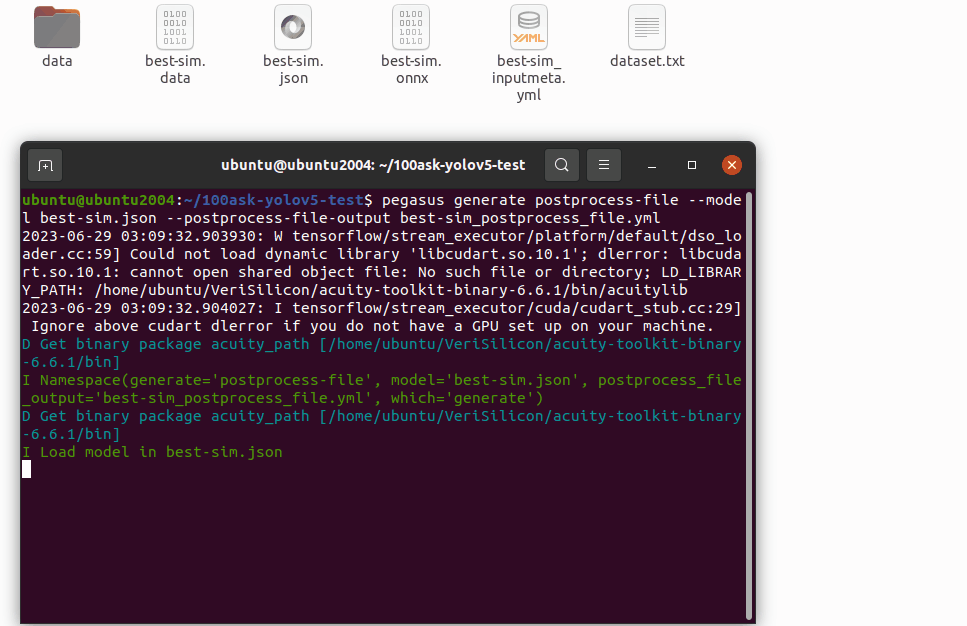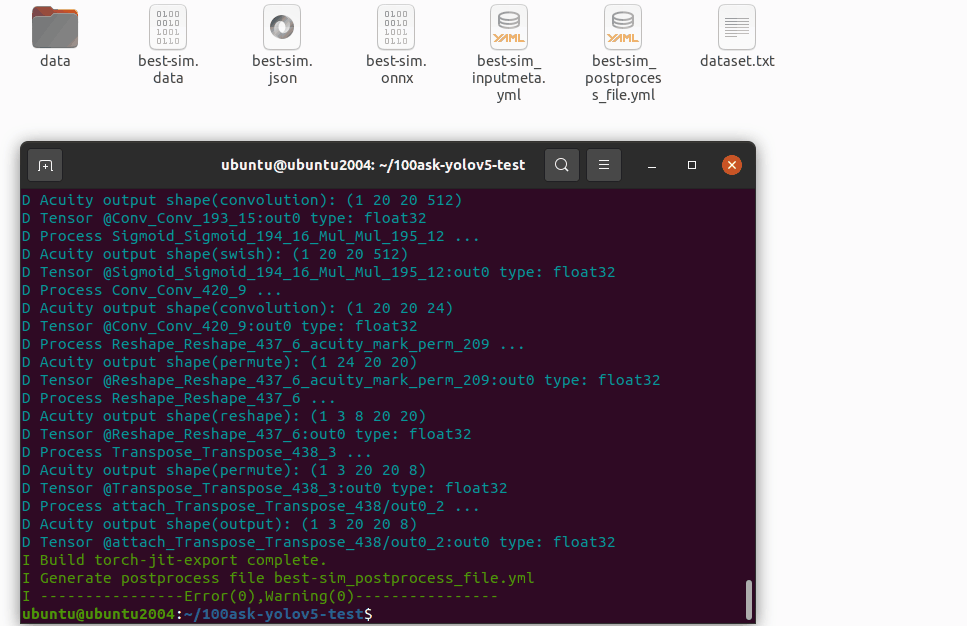
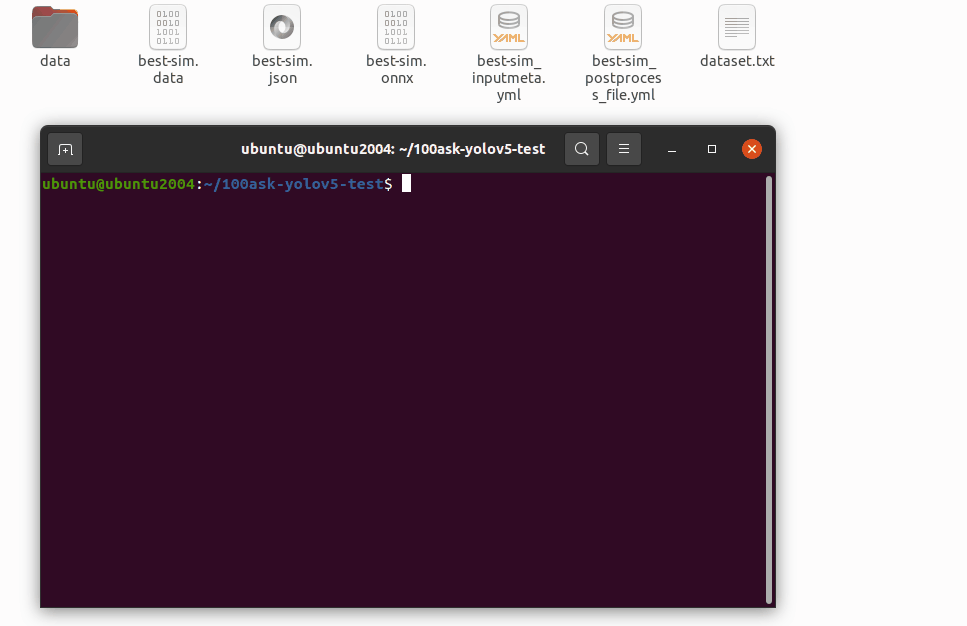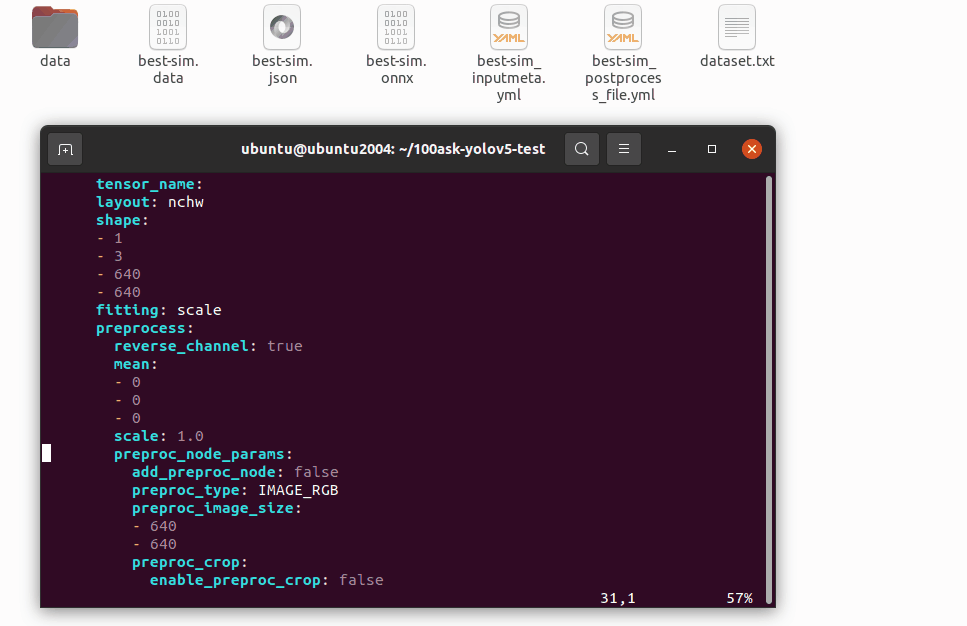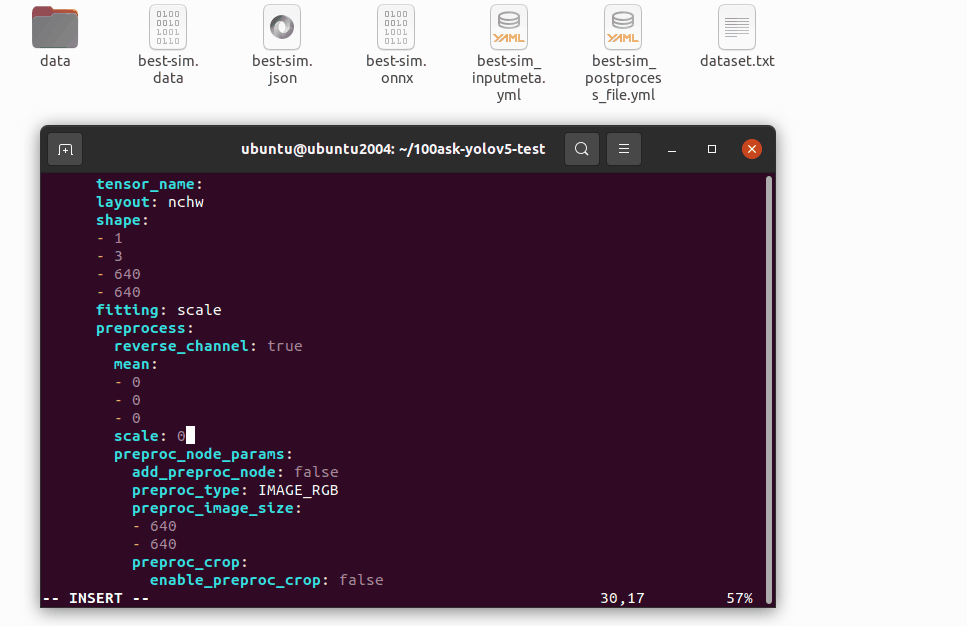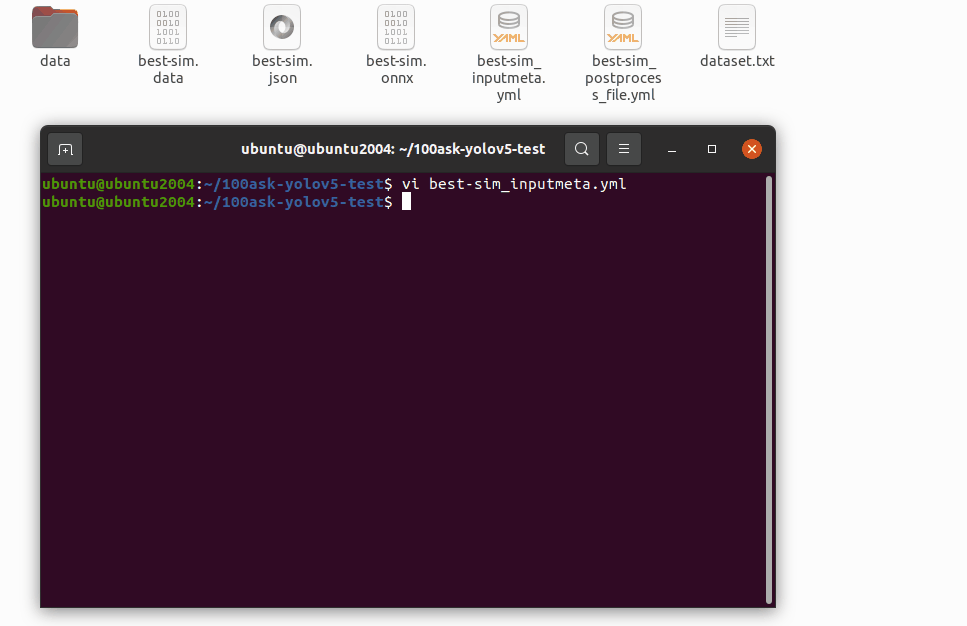
修改 best-sim_inputmeta.yml 文件中的的 scale 参数为 0.0039216(1/255),目的是对输入 tensor 进行归一化,和网络进行训练的时候是对应的。
vi best-sim_inputmeta.yml
修改过程如下图所示:
15.4 量化
生成量化表文件,使用非对称量化,uint8,修改 --batch-size 参数为你的 dataset.txt 里提供的图片数量。如果原始网络使用固定的batch_size,请使用固定的batch_size,如果原始网络使用可变batch_size,请将此参数设置为1。
pegasus quantize --model best-sim.json --model-data best-sim.data --batch-size 1 --device CPU --with-input-meta best-sim_inputmeta.yml --rebuild --model-quantize best-sim.quantize --quantizer asymmetric_affine --qtype uint8
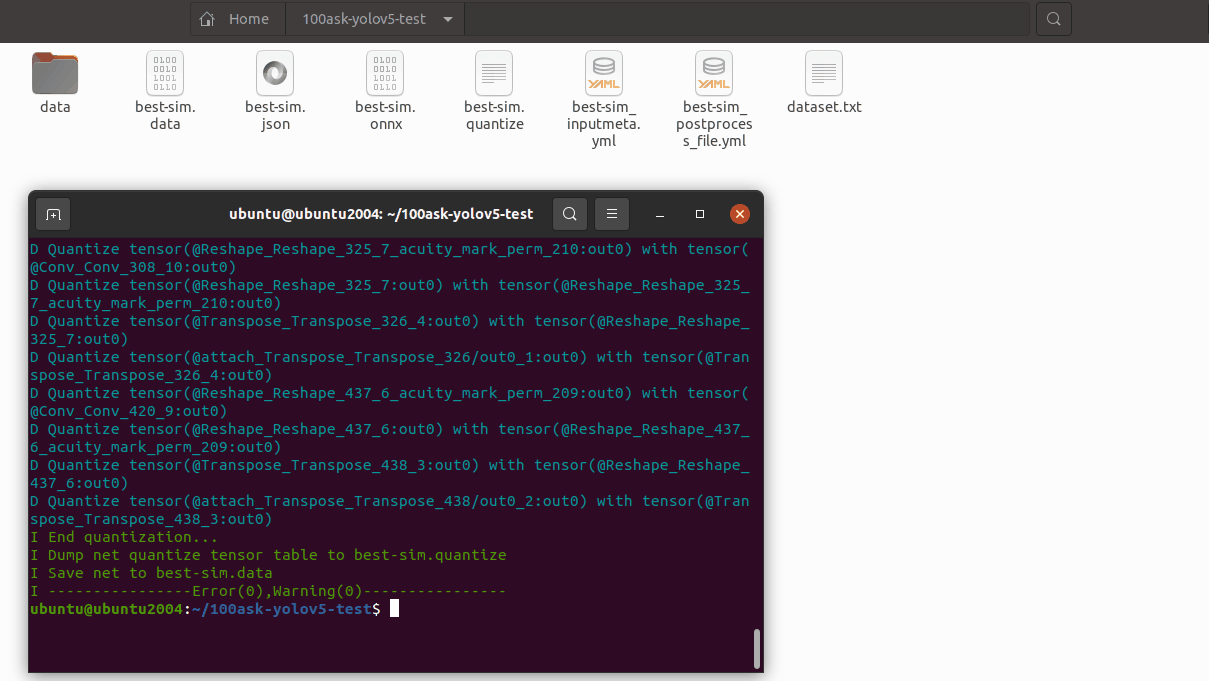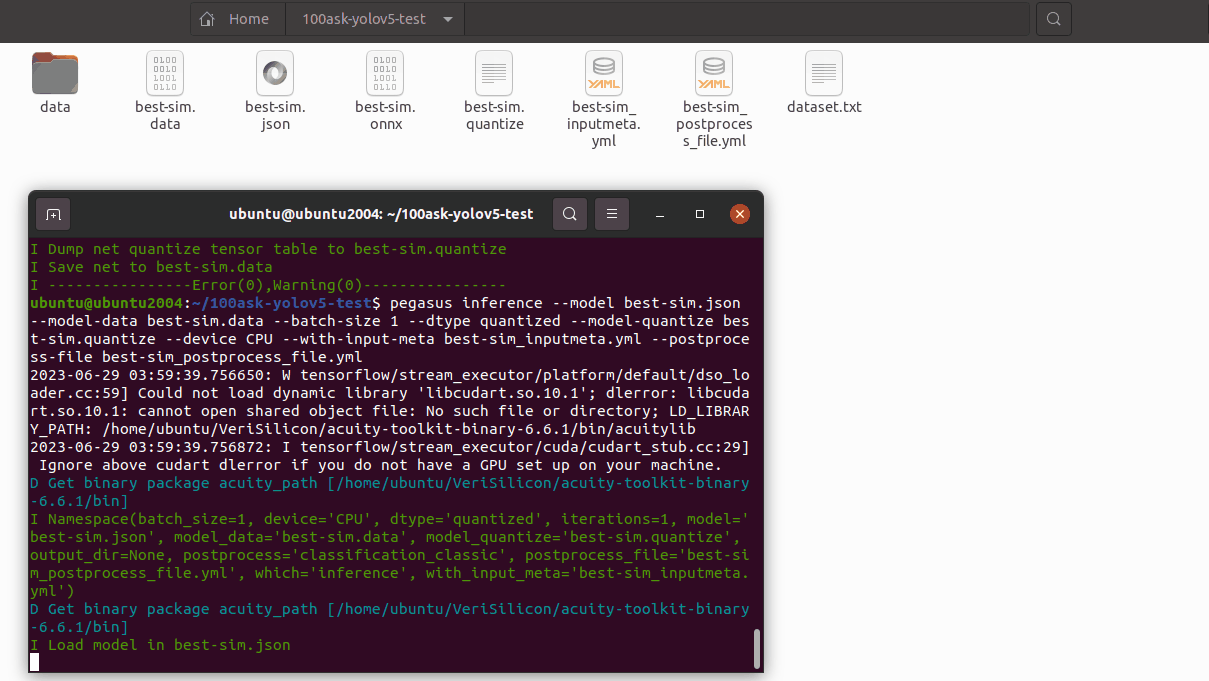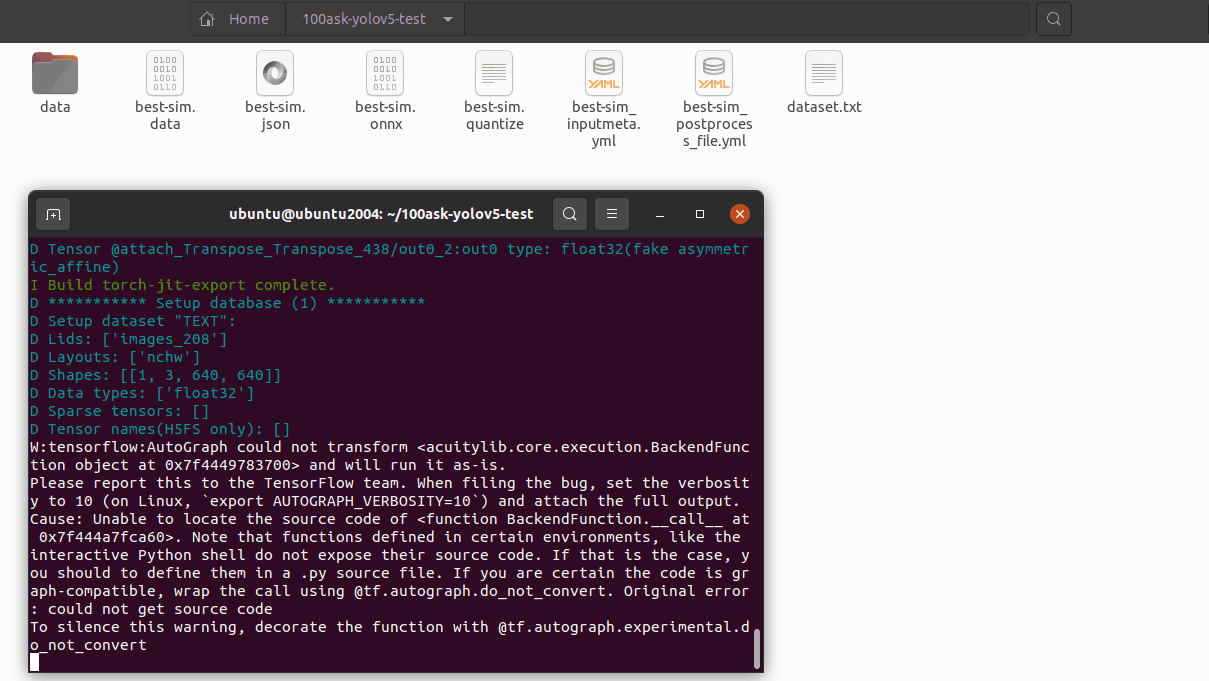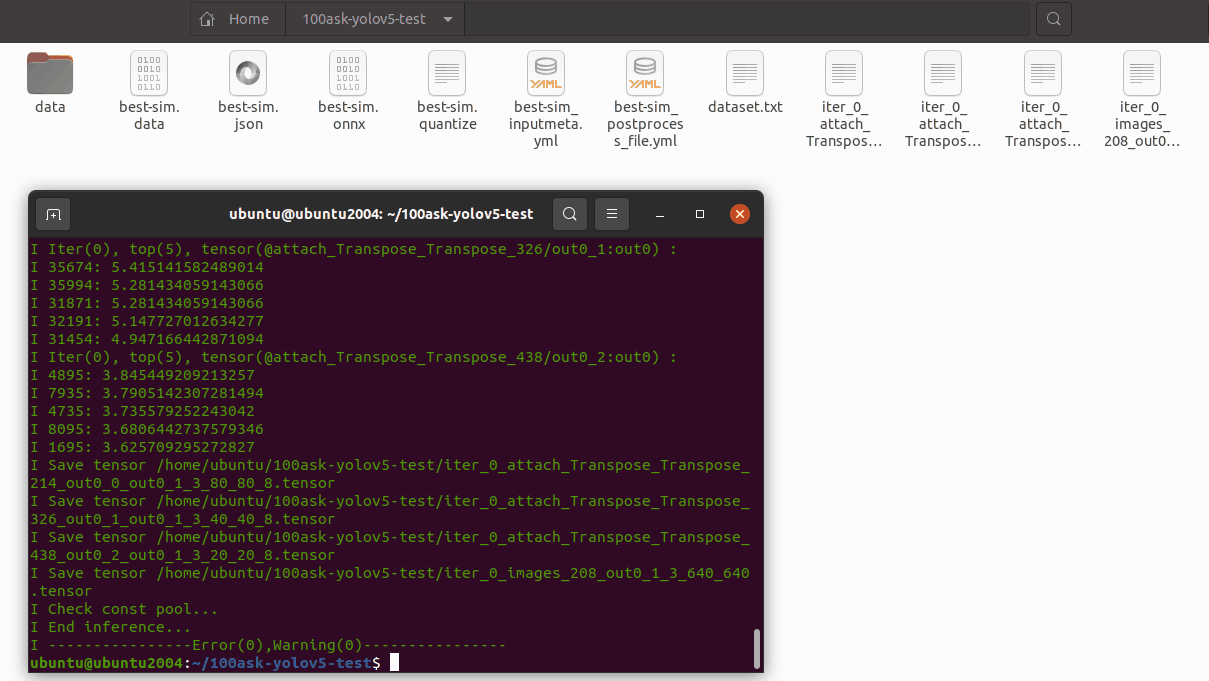
15.5 预推理
利用前文的量化表执行预推理,得到推理 tensor
pegasus inference --model best-sim.json --model-data best-sim.data --batch-size 1 --dtype quantized --model-quantize best-sim.quantize --device CPU --with-input-meta best-sim_inputmeta.yml --postprocess-file best-sim_postprocess_file.yml
15.6 导出模板代码与模型
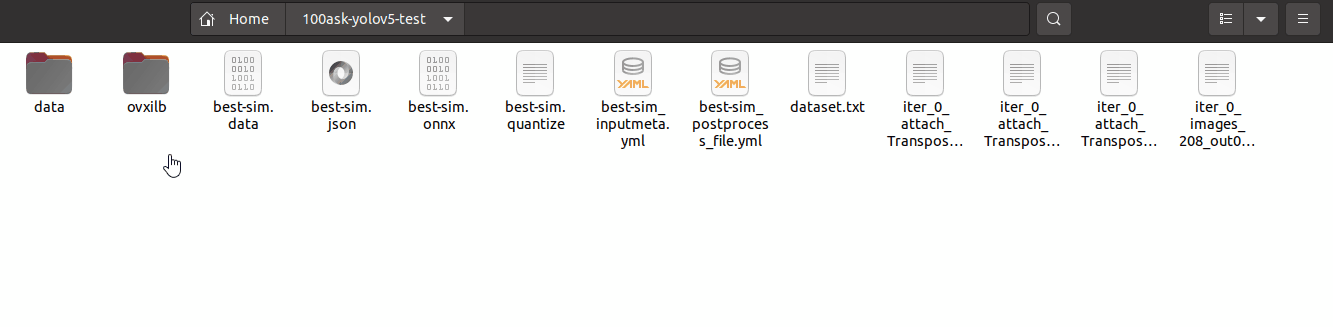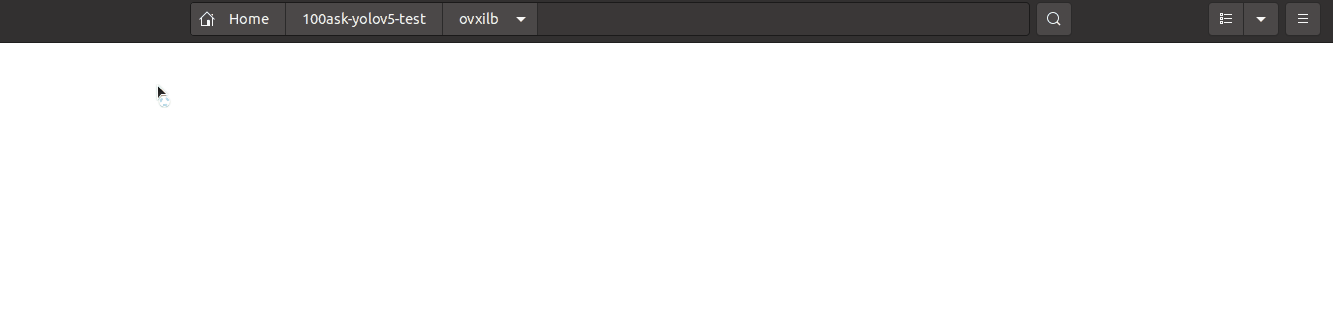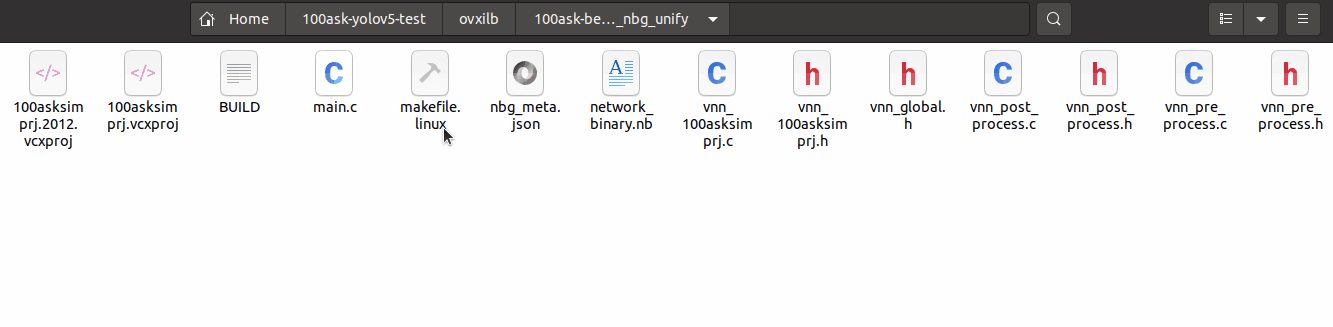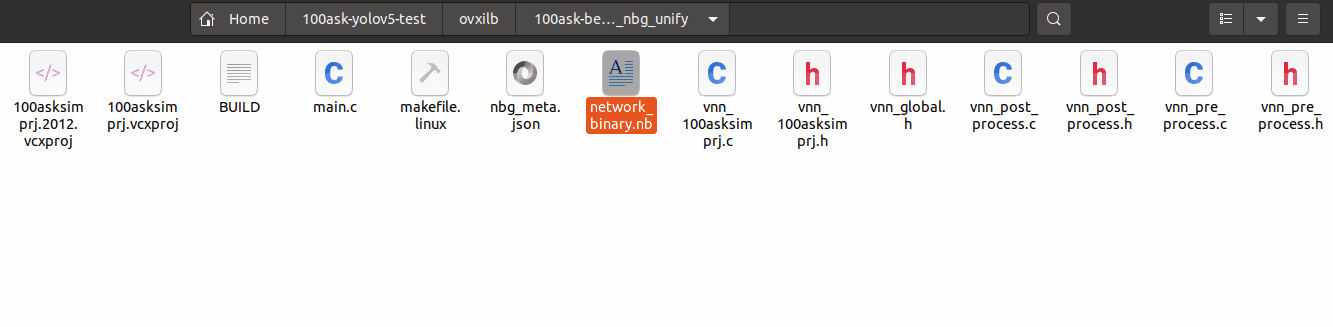
输出的模型可以在 ovxilb/100ask-best-sim_nbg_unify 文件夹中找到network_binary.nb模型文件。
pegasus export ovxlib --model best-sim.json --model-data best-sim.data --dtype quantized --model-quantize best-sim.quantize --batch-size 1 --save-fused-graph --target-ide-project 'linux64' --with-input-meta best-sim_inputmeta.yml --output-path ovxilb/100ask-best-sim/100ask-simprj --pack-nbg-unify --postprocess-file best-sim_postprocessmeta.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK}
可以进入下图所示目录中将network_binary.nb模型文件拷贝出来备用。
16.端侧部署
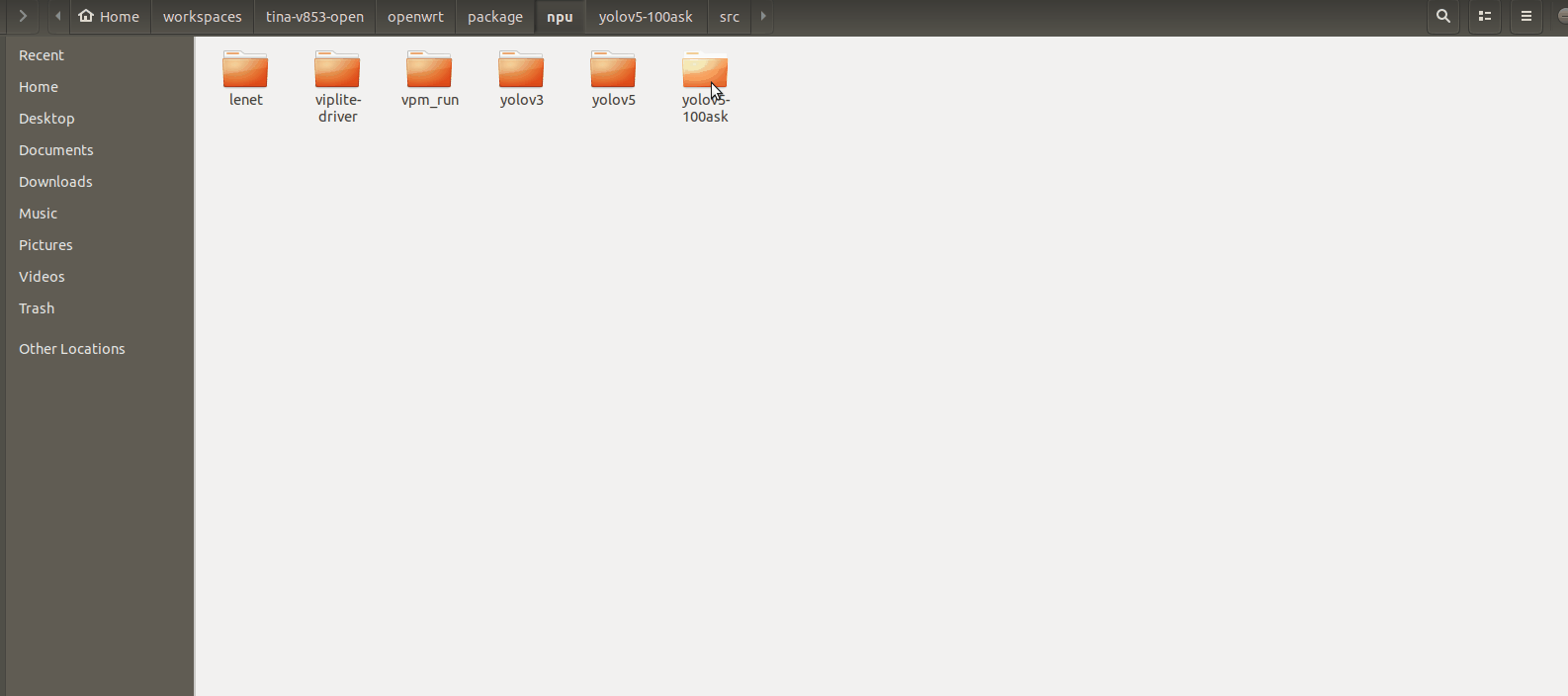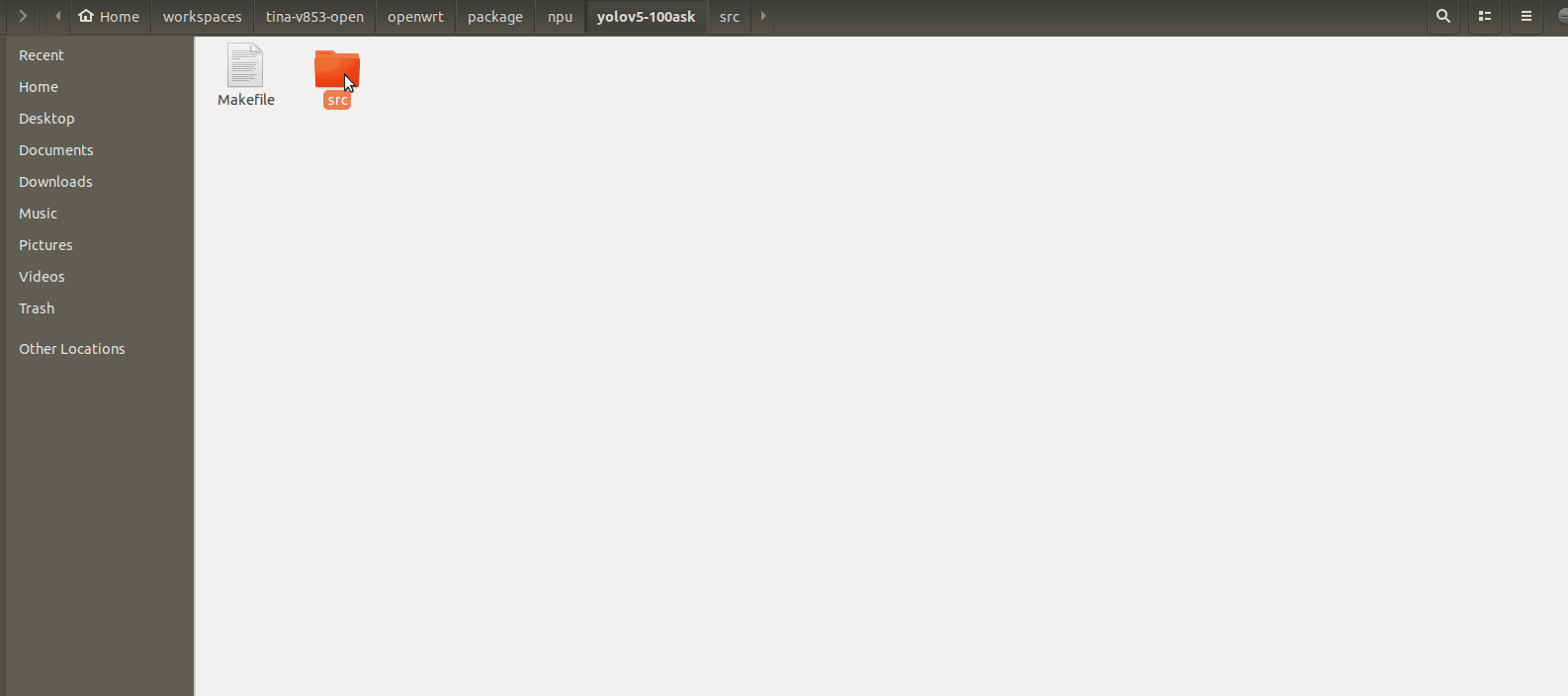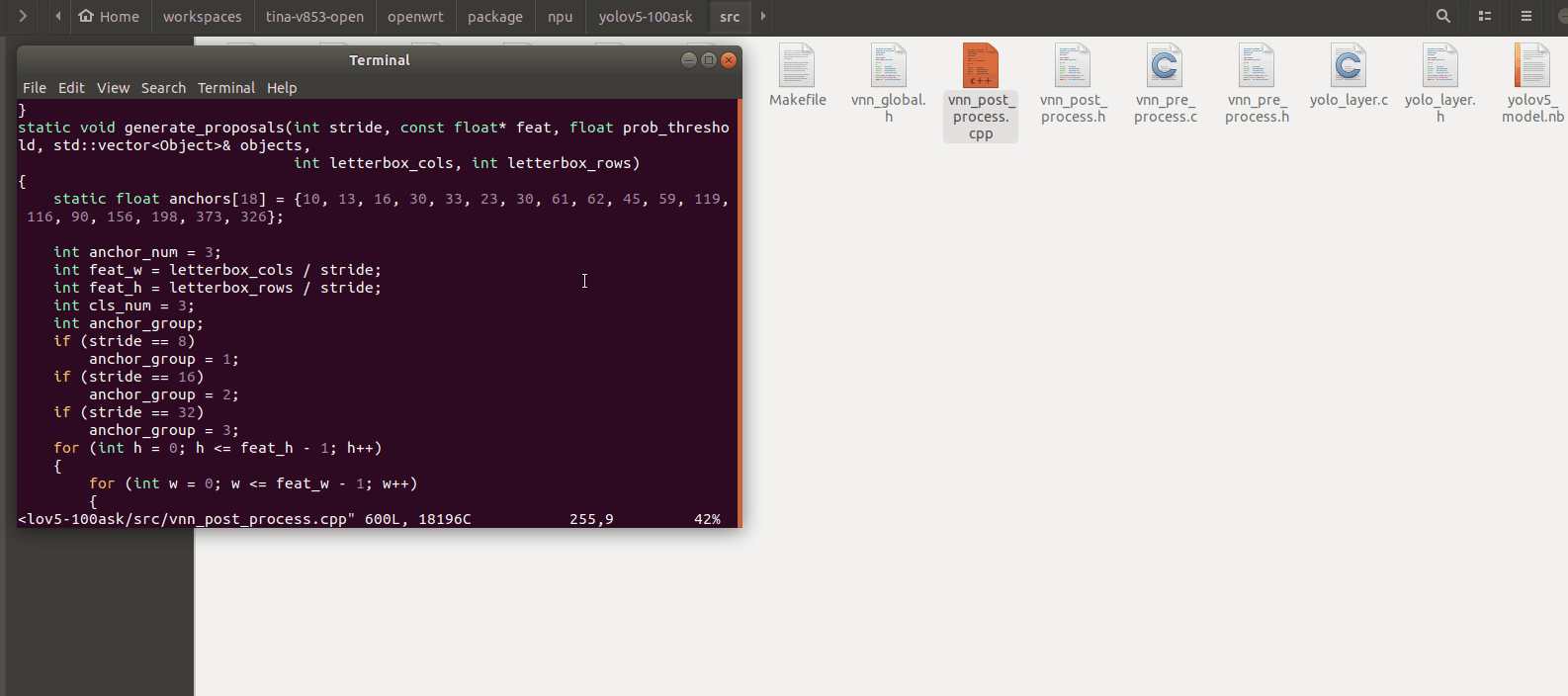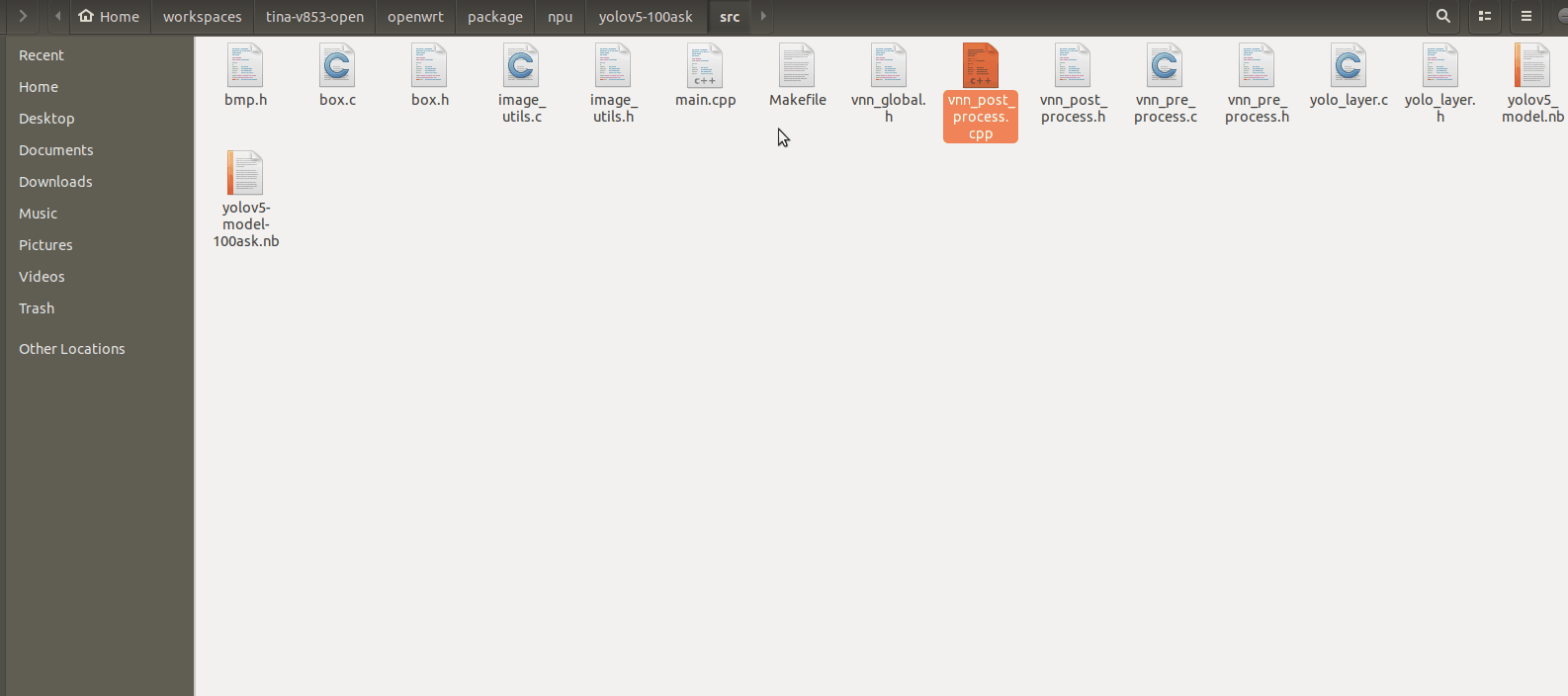
这里引用上一篇《100ASK-V853-PRO开发板支持yolov5模型部署》我们编写的yolov5端侧部署程序,这里进入端侧部署程序文件夹中拷贝一份新程序进行修改。主要修改vnn_post_process.cpp程序。
16.1 修改draw_objects函数
修改draw_objects函数中的类名,这里我训练的模型的类别分别是T113、K510、V853
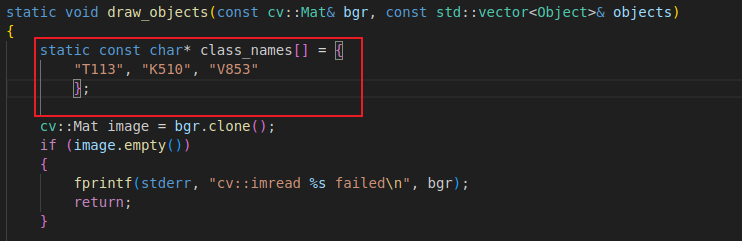
类别名称需要yolov5-6.0项目data目录下data.yaml对应
16.2 修改generate_proposals函数
修改generate_proposals函数中的类类别数量为您类别数量。假设我训练的类别总共有T113、K510、V853,这3个类别,修改为3即可。
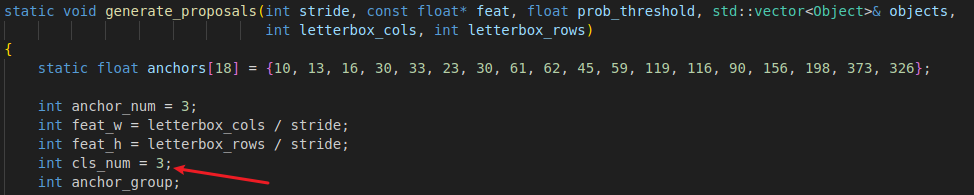
修改后的文件如下所示:
16.3 编译
book@100ask:~/workspaces/tina-v853-open$ source build/envsetup.sh
...
book@100ask:~/workspaces/tina-v853-open$ lunch
...1
...
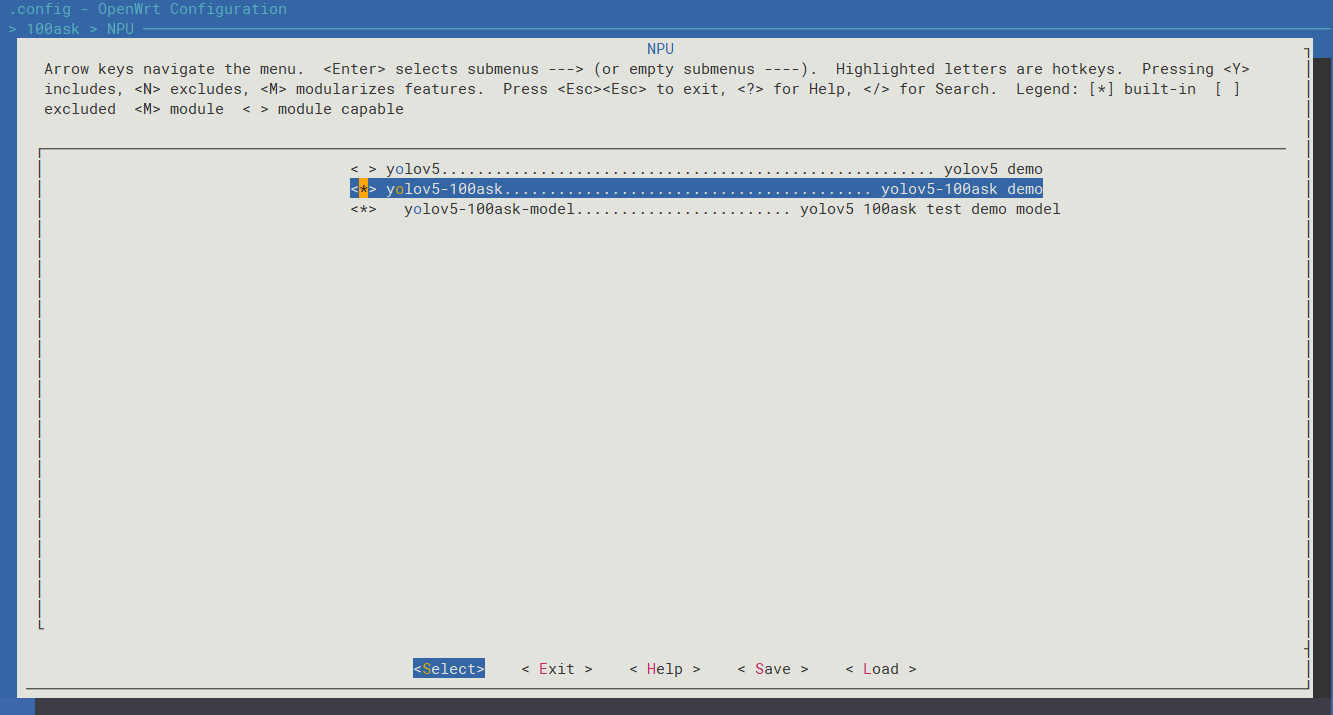
进入menuconfig选中yolov5-100ask配置,输入
make menuconfig
进入如下目录中
100ask
NPU
<*> yolov5-100ask… yolov5-100ask demo
编译并生成镜像
book@100ask:~/workspaces/tina-v853-open$ make
...
book@100ask:~/workspaces/tina-v853-open$ pack
编译完成后使用全志烧写工具烧录镜像。
16.4 测试
主机端:
传入640*640的图像文件和network_binary.nb模型文件
book@100ask:~/workspaces/testImg$ adb push test-100ask.jpg /mnt/UDISK
test-100ask.jpg: 1 file pushed. 0.6 MB/s (51039 bytes in 0.078s)
book@100ask:~/workspaces/testImg$ adb push network_binary.nb /mnt/UDISK
network_binary.nb: 1 file pushed. 0.7 MB/s (7409024 bytes in 10.043s)
开发板端:
进入/mnt/UDISK/目录下
root@TinaLinux:/# cd /mnt/UDISK/
root@TinaLinux:/mnt/UDISK# ls
lost+found network_binary.nb overlay test-100ask.jpg
运行yolov5检测程序
yolov5-100ask network_binary.nb test-100ask.jpg
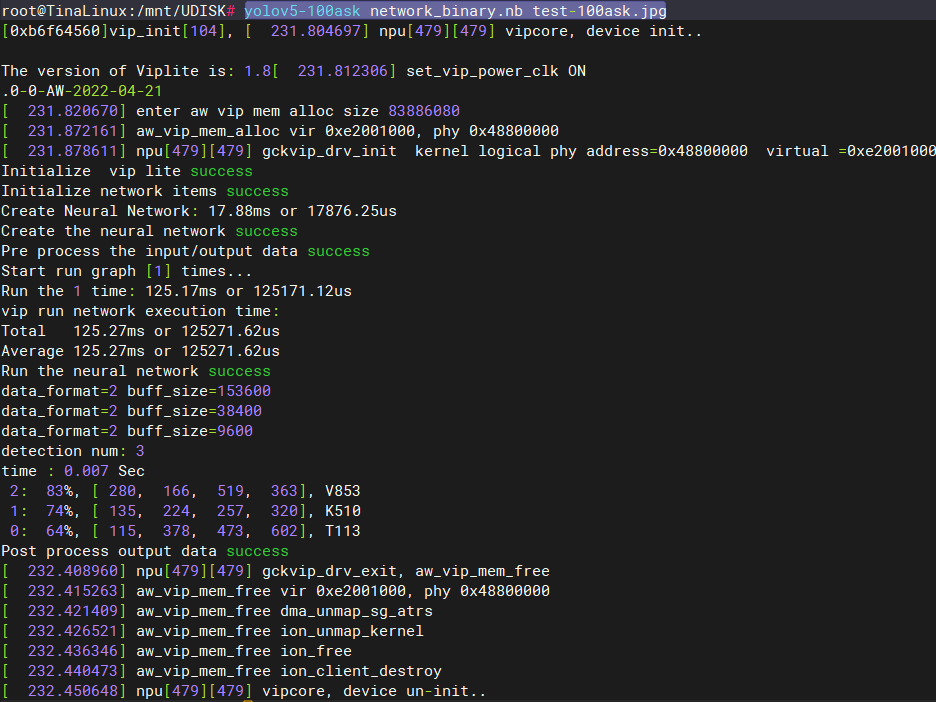
执行完成后会在当前目录下生成输出文件yolov5_out.jpg
root@TinaLinux:/mnt/UDISK# ls
lost+found overlay yolov5_out.jpg
network_binary.nb test-100ask.jpg
主机端:
拉取开发板端的输出图像yolov5_out.jpg
book@100ask:~/workspaces/testImg$ adb pull /mnt/UDISK/yolov5_out.jpg ./
/mnt/UDISK/yolov5_out.jpg: 1 file pulled. 0.8 MB/s (98685 bytes in 0.116s)


